LLM中常用的位置编码原理及其代码
一、位置编码
位置编码用于在输入序列中标记每个单词或标记的位置,这有助于模型理解输入序列中各个部分的相对位置,从而更好地捕捉序列中的长距离依赖关系。换言之,如果仅在查询(Q)和键(K)上使用位置编码,当我们计算 $QK^T$ 时,模型可以得到不同词之间的相似度得分。例如,”猫”和”狗”之间的得分理论上应该比较高。然而,仅通过计算这些得分,模型可能会忽略掉文本中的局部依赖关系(即相邻的token之间的得分应该也较高)。因此,位置编码有助于模型不仅理解长距离依赖,还能关注局部的顺序信息。一般而言就是计算得到位置编码之后将其与input embedding进行相加得到结果。对于位置编码借用论文中的定义:定义输入$N$个tokens:$S_N={w_i}_{i=1}^{N}$,并且在Transformer中要使用(对QKV)位置编码:
\[q_m=f_q(x_m,m)\\ k_n=f_k(x_n,n)\\ v_n=f_v(x_n,n)\]简单对比如下:
| 类型 | 说明 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 绝对位置编码 | 每个位置都有一个固定的编码,通常使用正弦和余弦函数生成的编码。 | 简单易理解,广泛应用于标准的 Transformer 模型中。 | 无法处理长距离依赖,难以泛化到不同长度的序列。 | 适用于较短文本的模型,序列长度相对固定的任务。 |
| 相对位置编码 | 通过对查询和键的相对位置差进行编码,使得模型在计算注意力时考虑相对距离。 | 能够处理长序列中的长距离依赖关系,动态建模位置差。 | 相比绝对位置编码,计算复杂度更高,模型实现也较为复杂。 | 适用于长序列建模,语言模型等需要建模长距离依赖的任务。 |
| RoPE (旋转位置编码) | 一种改进的相对位置编码方法,通过旋转变换将相对位置差引入注意力计算。 | 通过旋转方式考虑相对位置,能够捕捉长距离依赖,且计算更加高效。 | 实现相对复杂,旋转操作可能增加一些计算开销。 | 适用于需要捕捉长序列依赖的任务,如文本生成、机器翻译等。 |
| Learned Position Encoding | 位置编码通过学习得到,而不是通过固定的数学公式生成。 | 可以根据数据自适应学习位置编码,具有更强的表达能力。 | 需要额外的学习参数,并且可能受到数据集的限制,难以泛化到其他任务或数据集。 | 适用于大规模数据训练,模型需要从数据中自动学习位置关系的场景。 |
| Rotary Position Embedding (RoPE) | 使用旋转变换的相对位置编码,通常与绝对位置编码结合使用,来增强 Transformer 模型的长距离依赖建模能力。 | RoPE 相比传统的位置编码方法具有更好的扩展性,特别适用于长文本或长序列,提升了处理长距离依赖的能力。 | 相较于传统位置编码和其他相对位置编码方法,RoPE 的实现和理解略为复杂,增加了计算的复杂度。 | 适用于需要建模长序列和长距离依赖的任务,如文本生成、语言建模等。 |
1、Absolute Positon Embedding
绝对位置编码常规做法是在词嵌入上补充一个位置编码向量然后乘对应的变换矩阵:
\[f_{t\in{q,k,v}}=W_{t\in{q,k,v}}(x_i+p_i)\]最原始的方法就是直接使用Sinusoidal函数:
另外一种方式是使用 学习位置编码(用一个学习矩阵表示即可):
\[p_i = W,W:[seq_len, embed_dim]\]随之而来,使用绝对位置编码存在一个缺陷(以第一种为例):每个token的位置编码都是固定的,这意味着每个词的位置信息是独立的,无法灵活地体现不同“单词”之间的相对距离。具体来说,绝对位置编码只为每个token分配一个固定的位置信息,不会根据token之间的相对位置关系来调整其编码。因此,它不能很好地反映序列中不同单词之间的相对距离,尤其是在处理长距离依赖关系时,可能无法准确捕捉到不同位置的语义依赖
2、Relative Position Embedding
以Transformer-XL为例,相对位置编码通过引入动态计算的 相对位置差 来替代传统的 绝对位置编码,这种方法能够有效地捕捉长文本中的长距离依赖。每一层的自注意力机制会结合相对位置编码,进而增强模型的上下文理解能力,尤其在处理长序列时,Transformer-XL 可以显著减少计算开销,并提高模型对长距离依赖的建模能力。
3、RoPE
按照论文中描述对于Q和K之间的内积操作可以用一个函数g进行表示,该函数输入为词嵌入向量$x_m$以及$x_n$和他们之间的相对位置$m-n$,因此可以假设下面公式成立:
对于$f_q$以及 $f_k$都包含位置信息,希望通过一个内积函数,得到一个函数 $g$(包含相对位置m-n)以二维例子为例,
\[\begin{aligned} f_{q}(\boldsymbol{x}_{m},m) & =(\boldsymbol{W}_q\boldsymbol{x}_m)e^{im\theta} \\ f_k(\boldsymbol{x}_n,n) & =(\boldsymbol{W}_k\boldsymbol{x}_n)e^{in\theta} \\ g(\boldsymbol{x}_{m},\boldsymbol{x}_{n},m-n) & =\mathrm{Re}[(\boldsymbol{W}_q\boldsymbol{x}_m)(\boldsymbol{W}_k\boldsymbol{x}_n)^*e^{i(m-n)\theta}] \end{aligned}\]借鉴中的证明,对于$f_{q}(\boldsymbol{x}_{m},m)$其中指数函数$e^{imx}$可以根据欧拉公式改写为:$e^{imx}=cos(m\theta)+isin(m\theta)$,因为是以2维度为例因此对于前部分($W_qx_m$)可以改写为:
\[q_m=W_{q} x_{m}=\left(\begin{array}{ll} W_{q}^{(11)} & W_{q}^{(12)} \\ W_{q}^{(21)} & W_{q}^{(22)} \end{array}\right)\binom{x_{m}^{(1)}}{x_{m}^{(2)}}\]类似的$q_m$也可以用复数进行表示:$q_m=[q_m^{(1)},q_m^{(2)}]=[q_m^{(1)}+iq_m^{(2)}]$,因此代入可以得到:$f_q=(q_m^{(1)}+iq_m^{(2)})(cos(m\theta)+isin(m\theta))$展开得到:
\[f_q=\left[ q_m^{(1)} \cos(m\theta) - q_m^{(2)} \sin(m\theta), q_m^{(2)} \cos(m\theta) + q_m^{(1)} \sin(m\theta) \right]\\ = \left( \begin{matrix} \cos(m\theta) & -\sin(m\theta) \\ \sin(m\theta) & \cos(m\theta) \end{matrix} \right) \left( \begin{matrix} q_m^{(1)} \\ q_m^{(2)} \end{matrix} \right)\]从上面公式从几何角度出发(假设$m \theta= 45°$)发现就是简单一个旋转操作,但是用到的也是 绝对位置信息:
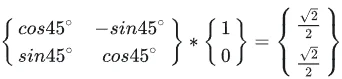
那么内积计算就可以表示为:
\[g(\mathbf{x}_m, \mathbf{x}_n, m-n) = \begin{pmatrix} \mathbf{q}_m^{(1)} & \mathbf{q}_m^{(2)} \end{pmatrix} \begin{pmatrix} \cos((m-n)\theta) & -\sin((m-n)\theta) \\ \sin((m-n)\theta) & \cos((m-n)\theta) \end{pmatrix} \begin{pmatrix} \mathbf{k}_n^{(1)} \\ \mathbf{k}_n^{(2)} \end{pmatrix}\]最开始$f_q$和 $f_k$使用的都是绝对位置信息,通过内积计算,最后实现 相对位置编码。推广到n维可以最后得到:
\[\boldsymbol{R}_{\Theta, m}^{d} \boldsymbol{x}=\left(\begin{array}{c} x_{0} \\ x_{1} \\ x_{2} \\ x_{3} \\ \vdots \\ x_{d-2} \\ x_{d-1} \end{array}\right) \otimes\left(\begin{array}{c} \cos m \theta_{0} \\ \cos m \theta_{0} \\ \cos m \theta_{1} \\ \cos m \theta_{1} \\ \vdots \\ \cos m \theta_{d / 2-1} \\ \cos m \theta_{d / 2-1} \end{array}\right)+\left(\begin{array}{c} -x_{1} \\ x_{0} \\ -x_{3} \\ x_{2} \\ \vdots \\ -x_{d-1} \\ x_{d-2} \end{array}\right) \otimes\left(\begin{array}{c} \sin m \theta_{0} \\ \sin m \theta_{0} \\ \sin m \theta_{1} \\ \sin m \theta_{1} \\ \vdots \\ \sin m \theta_{d / 2-1} \\ \sin m \theta_{d / 2-1} \end{array}\right)\]从几何角度出发进行理解:
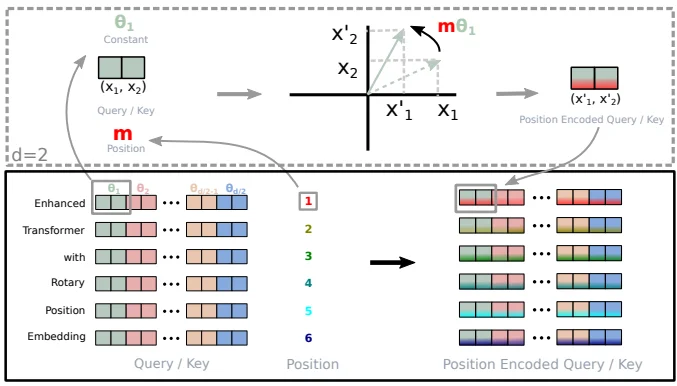
1.对于位置为m的d维q向量,我们分为d/2组,每两个相邻维度为一组,共同旋转一个角度$m\theta_i$。
2.$\theta_i$是一个这是一个从1渐变到接近于0的函数,因此,前面维度的$\theta_i$旋转的更快,后面的旋转的更慢
借用博客中的结论:
1、RoPE具有良好的外推性(指的是:大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。例如,如果一个模型在训练时只使用了512个 token 的文本,那么在预测时如果输入超过512个 token,模型可能无法正确处理。这就限制了大模型在处理长文本或多轮对话等任务时的效果。),应用到Transformer中体现出较好的处理长文本的能力。
二、tokenizer
tokenizer的原理十分简单,就是将文本进行切割,然后用数字去代表这些文本。常见的主要有如下几类:
1、word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .]
2、character:按照单字符进行分词,就是以char为最小粒度。 如:Today is sunday. 则会分割成[t, o, d,a,y, .... ,s,u,n,d,a,y, .]
3、subword:按照词的subword进行分词。如:Today is sunday. 则会分割成[to, day,is , s,un,day, .]
各类LLM所使用分词器如下:
| 模型 | 分词器方法 |
|---|---|
| GPT-3 (OpenAI) | Byte Pair Encoding (BPE) |
| BERT (Google) | WordPiece |
| T5 (Google) | SentencePiece |
| RoBERTa (Facebook) | Byte Pair Encoding (BPE) |
| XLNet (Google/CMU) | SentencePiece |
| ALBERT (Google) | SentencePiece |
| DistilBERT (Hugging Face) | WordPiece |
| ELECTRA (Google) | WordPiece |
| BLOOM (BigScience) | SentencePiece |
| GPT-4 (OpenAI) | Byte Pair Encoding (BPE) |
| Mistral (Mistral) | Byte Pair Encoding (BPE) |
1、BPE(Byte Pair Encoding)
基本思路是将使用最频繁的字节用一个新的字节组合代替,比如用字符的n-gram替换各个字符.例如,假设(‘A’, ‘B’) 经常顺序出现,则用一个新的标志’AB’来代替它们.分词算法(word segmentation)构建BPE,并将其应用于机器翻译任务中.论文提出的基本思想是,给定语料库,初始词汇库仅包含所有的单个字符.然后,模型不断地将出现频率最高的n-gram pair作为新的n-gram加入到词汇库中,直到词汇库的大小达到我们所设定的某个目标为止。
sentencepiece是一个google开源的自然语言处理工具包,支持bpe、unigram等多种分词方法。其优势在于:bpe、unigram等方法均假设输入文本是已经切分好的,只有这样bpe才能统计词频(通常直接通过空格切分)。但问题是,汉语、日语等语言的字与字之间并没有空格分隔。sentencepiece提出,可以将所有字符编码成Unicode码(包括空格),通过训练直接将原始文本(未切分)变为分词后的文本,从而避免了跨语言的问题。[^1]
论文中给出的算法例子如上图所示。算法从所有的字符开始,首先将出现频率最高的 (e, s) 作为新的词汇加入表中,然后是(es, t)。以此类推,直到词汇库大小达到我们设定的值。更清晰的过程如下图所示。其中,Dictionary左列表示单词出现的频率。

以sentencepiece测试为例(输入模型的句子必须是单独成行(每一个文本都是单独一行)):
# 第一步预训练一个分词
def train(input_file, vocab_size, model_name, model_type, character_coverage):
"""
search on https://github.com/google/sentencepiece/blob/master/doc/options.md to learn more about the parameters
:param input_file: one-sentence-per-line raw corpus file. No need to run tokenizer, normalizer or preprocessor.
By default, SentencePiece normalizes the input with Unicode NFKC.
You can pass a comma-separated list of files.
:param vocab_size: vocabulary size, e.g., 8000, 16000, or 32000
:param model_name: output model name prefix. <model_name>.model and <model_name>.vocab are generated.
:param model_type: model type. Choose from unigram (default), bpe, char, or word.
The input sentence must be pretokenized when using word type.
:param character_coverage: amount of characters covered by the model, good defaults are: 0.9995 for languages with
rich character set like Japanse or Chinese and 1.0 for other languages with
small character set.
"""
input_argument = '--input=%s --model_prefix=%s --vocab_size=%s --model_type=%s --character_coverage=%s ' \
'--pad_id=0 --unk_id=1 --bos_id=2 --eos_id=3 '
cmd = input_argument % (input_file, model_name, vocab_size, model_type, character_coverage)
spm.SentencePieceTrainer.Train(cmd)
if __name__ == "__main__":
en_input = '../data/corpus.en'
en_vocab_size = 32000
en_model_name = 'eng'
en_model_type = 'bpe'
en_character_coverage = 1
train(en_input, en_vocab_size, en_model_name, en_model_type, en_character_coverage)
sp = spm.SentencePieceProcessor()
text = "ZUEL was established in 2000 with the merge of the then Central South University of Finance and Economics and then Central South Political Science and Law College. Its root could be traced to 1948 when then Zhongyuan University was founded in the Province of Henan and later moved to Wuhan."
sp.load('../Zh-En-translate/tokenizer/eng.model')
print(sp.EncodeAsPieces(text))
print(sp.EncodeAsIds(text))
a = [24588, 3276, 219, 2589, 26, 3203, 115, 10, 20943, 34, 10, 1041, 1929, 1204, 3640, 34, 6958, 39, 8385, 39, 1041, 1929, 1204, 6235, 9093, 39, 6024, 12285, 31843, 3362, 3899, 397, 55, 18112, 31, 20864, 479, 1041, 6723, 201, 31838, 6193, 3640, 219, 8186, 26, 10, 16839, 34, 8643, 18, 39, 2234, 4813, 31, 153, 28941, 31843]
print(sp.decode_ids(a))
输出结果:
['▁ZU', 'EL', '▁was', '▁established', '▁in', '▁2000', '▁with', '▁the', '▁merge', '▁of', '▁the', '▁then', '▁Central', '▁South', '▁University', '▁of', '▁Finance', '▁and', '▁Economics', '▁and', '▁then', '▁Central', '▁South', '▁Political', '▁Science', '▁and', '▁Law', '▁College', '.', '▁Its', '▁root', '▁could', '▁be', '▁traced', '▁to', '▁1948', '▁when', '▁then', '▁Zh', 'ong', 'y', 'uan', '▁University', '▁was', '▁founded', '▁in', '▁the', '▁Province', '▁of', '▁Hen', 'an', '▁and', '▁later', '▁moved', '▁to', '▁W', 'uhan', '.']
[24588, 3276, 219, 2589, 26, 3203, 115, 10, 20943, 34, 10, 1041, 1929, 1204, 3640, 34, 6958, 39, 8385, 39, 1041, 1929, 1204, 6235, 9093, 39, 6024, 12285, 31843, 3362, 3899, 397, 55, 18112, 31, 20864, 479, 1041, 6723, 201, 31838, 6193, 3640, 219, 8186, 26, 10, 16839, 34, 8643, 18, 39, 2234, 4813, 31, 153, 28941, 31843]
ZUEL was established in 2000 with the merge of the then Central South University of Finance and Economics and then Central South Political Science and Law College. Its root could be traced to 1948 when then Zhongyuan University was founded in the Province of Henan and later moved to Wuhan.
对于sentencepiece分词器,一般来说流程为:
1、用自己数据进行训练得到“分词器”
2、直接调用分词器进行encoder/decoder:
import sentencepiece as spm
def chinese_tokenizer_load(path):
sp_chn = spm.SentencePieceProcessor()
sp_chn.Load(path)
return sp_chn
def english_tokenizer_load(path):
sp_eng = spm.SentencePieceProcessor()
sp_eng.Load(path)
return sp_eng
sp_chn = chinese_tokenizer_load('..')
sp_eng = english_tokenizer_load('..')
out_a = sp_chn.EncodeAsPieces('介绍Tokenizer使用方法')
print(out_a)
out_b = sp_eng.DecodeIds(out_a)
print(out_b)
# ['▁', '介绍', 'T', 'ok', 'en', 'iz', 'er', '使用', '方法']
# 介绍Tokenizer使用方法
2、使用预训练好的tokenizer
1.OpenAI:https://platform.openai.com/tokenizer
2.Huggingface:https://github.com/huggingface/tokenizers
3.sentencepiece:https://github.com/google/sentencepiece
类似的,如果我需要直接使用别人已经训练好的的tokenizer(GLM,Qwen)代码如下:
from ChatGLM.tokenization_chatglm import ChatGLMTokenizer
from ChatGLM.tokenization_chatglm import ChatGLMTokenizer
from Qwen.tokenization_qwen import QWenTokenizer
tokenizer_glm = ChatGLMTokenizer(
vocab_file="./ChatGLM/tokenizer.model"
)
tokenizer_qwen = QWenTokenizer('./Qwen/qwen.tiktoken')
text = "介绍Tokenizer使用方法!"
encoded_input_glm = tokenizer_glm(text, return_tensors='pt')
encoded_input_qwen = tokenizer_qwen(text, 'pt')
print(encoded_input_glm, encoded_input_qwen)
decoded_output_glm = tokenizer_glm.decode(encoded_input_glm["input_ids"][0])
decoded_output_qwen = tokenizer_qwen.decode(encoded_input_qwen["input_ids"][:-1])
print(decoded_output_glm, decoded_output_qwen)
# {'input_ids': tensor([[64790, 64792, 30910, 32025, 12997, 6486, 31695, 31847, 30992]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'position_ids': tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8]])} {'input_ids': [100157, 37434, 37029, 39907, 0, 417], 'token_type_ids': [0, 0, 0, 0, 0, 1], 'attention_mask': [1, 1, 1, 1, 1, 1]}
# 介绍Tokenizer使用方法! 介绍Tokenizer使用方法!
Notice
1、值得注意的是,一般来说文本预料,不如图片那般规整(图片可以直接修改尺寸到相同即可),文本可能长可能短,那么在data_loader时候就需要注意需要保证最后长度相同(1、提前固定到相同长度;2、在batch里面补充到相同长度)
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
class Dataset(Dataset):
def __init__():
...
def __len__():
...
def __getitem__():
...
def collate_fn(self, batch):
src_text = [x[0] for x in batch]
tgt_text = [x[1] for x in batch]
src_tokens = [[self.BOS] + self.sp_eng.EncodeAsIds(sent) + [self.EOS] for sent in src_text]
tgt_tokens = [[self.BOS] + self.sp_chn.EncodeAsIds(sent) + [self.EOS] for sent in tgt_text]
src = pad_sequence([torch.LongTensor(np.array(l_)) for l_ in src_tokens],
batch_first=True, padding_value=self.PAD)
trg = pad_sequence([torch.LongTensor(np.array(l_)) for l_ in tgt_tokens],
batch_first=True, padding_value=self.PAD)
....
return src_text, tgt_text, src, trg
参考
1、https://arxiv.org/pdf/2104.09864
2、https://zhuanlan.zhihu.com/p/642884818
3、https://kexue.fm/archives/8265
4、https://zhuanlan.zhihu.com/p/630696264
5、https://huggingface.co/THUDM/glm-4-9b-chat/tree/main
6、https://huggingface.co/Qwen/Qwen-7B/tree/main
7、https://arxiv.org/pdf/1901.02860
8、https://zhuanlan.zhihu.com/p/8306958113
9、https://arxiv.org/pdf/2502.20082
10、https://arxiv.org/pdf/2402.13753
