深度学习中常见的LLM微调技术及其代码
大语言模型微调,一般来说是指在一个预训练完成的LLM上去针对对应的下游任务进行微调,让其更加适应下游任务,一般来说可以:1、全面微调(对LLM中全部参数进行调整,如果模型参数量很大的时候这个花销是比较大的);2、部分参数微调
1、Prompt-tuning
“prompt” 指的是用户提供给模型的输入文本或指令,它用于引导模型生成相关的文本或完成特定的任务。prompt可以是一个问题、一句话、一个主题,或者是一段完整的文本。模型会根据prompt理解用户的意图,并生成相应的文本作为回应。值得注意的是,对于prompt会有下面两种不同的描述:
1、hard prompt:这种类型的 prompt 是模型输入的一部分,通常由用户直接提供的自然语言文本构成,模型在接受到这个文本后会根据文本的内容生成回应。硬提示是显式的,通常是文本的某一部分,用来明确指定模型的任务。例如,在文本生成任务中,用户可能输入:“请写一篇关于气候变化的文章”,这就是一个硬提示。硬提示的特点是它直接表达了用户的意图,通常不需要修改或调整。
2、soft prompt:软提示则是指通过某种方法(如优化算法或训练过程)生成的、在模型中以特定的向量形式存在的输入,它们并不是自然语言文本,而是“学习”到的潜在向量或嵌入表示。软提示并不是由用户手动编写的,而是在训练过程中或微调过程中,通过算法自动生成或优化得到的。这些向量通常不会直接呈现给用户,而是在模型内部起作用,作为一个“潜在的提示”来引导模型完成任务。
1.1 Prefix-Tuning
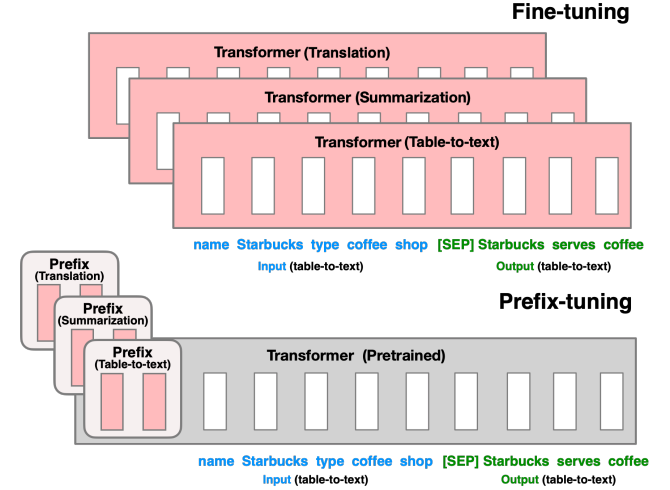
上面为全面微调Transformer全部参数,而下面为只微调Prefix(一种可学习的前缀),如下图描述一样:
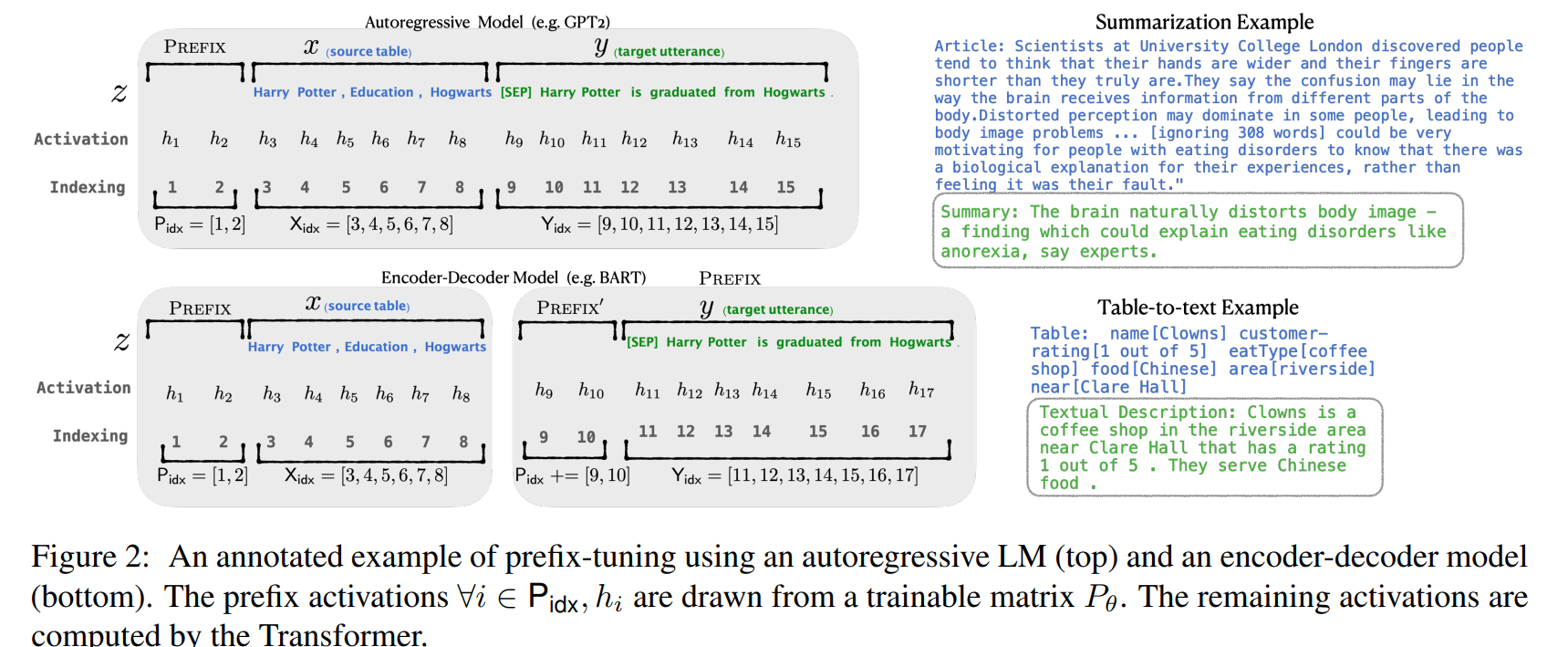
对于输入文本:$X=(x_1,…,x_n)$,我在其前面补充一个 前缀:$P=(p_1,…,p_m)$,前缀长度是远小于输入文本长度的,在微调过程中保持模型参数$\theta$保持不变,这样一来优化过程就变成了:
\[P^*=\arg\min_P\mathcal{L}(M(P\oplus X;\theta),Y)\]其中$P\oplus X$表示将前缀拼接到输入前面,训练过程中只优化前缀即可
1.2 P-Tuning
对于一段输入,我通过预先生成的Prompt进行embedding(代码中作者是通过LSTM对prompt的embedding进行训练)然后融合到input中,然后输入到预训练的模型中去,然后去将预训练模型参数以及LSTM计算得到的Prompt参数一起加入训练
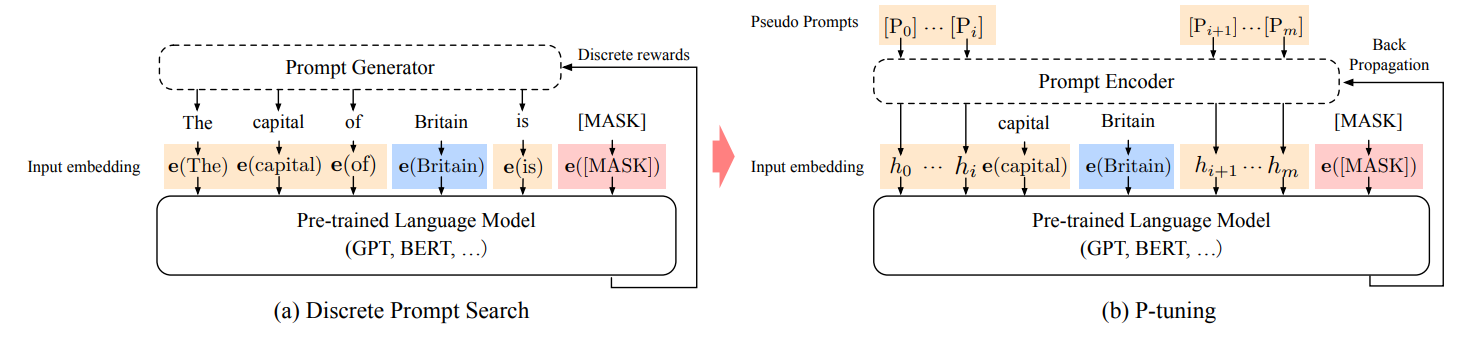
左侧为传统的Prompt处理方法,通过事先定义好的Prompt进行微调,P-tuning与之存在区别:用预训练词表中的unused token作为伪prompt「BERT的vocab里有unused 1 ~ unused99」,然后通过训练去更新这些token的参数也就是,P-tuning的Prompt不是显式的,不是我们可以看得懂的字符,而是一些隐式的、经过训练的、模型认为最好的prompt token。换言之,
1.3 P-Tuning v2
2、Parameter-efficient fine-tuning
参数高效的fine-tuning,简称PEFT,旨在在尽可能减少所需的参数和计算资源的情况下,实现对预训练语言模型的有效微调。它是自然语言处理(NLP)中一组用于将预训练语言模型适应特定任务的方法,其所需参数和计算资源比传统的fine-tuning方法更少
2.1 LoRA
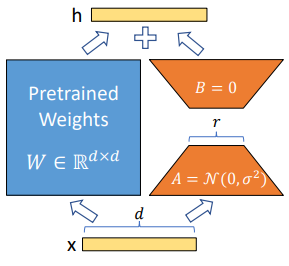
对于预训练权重:$W_0 \in R^{d \times k}$,可以将其表示成一种低序表示:$W_0 + \Delta W= W_0+ BA$ 其中:$B \in R ^{d \times r},A \in R ^{r \times k}$,其中r远小于$min(d,k)$。训练过程中$W_0$被冻结不接受更新,A,B作参数进行训练,得到:$h= W_0x+ \Delta Wx=W_0x+BAx$。这样一来就很大程度减小了参数调整(比如说:$W_0$:5x5的,设置B:5x1;A:1x5。这样一来较之25参数调整和(5,5)的参数调整,就小了很多)
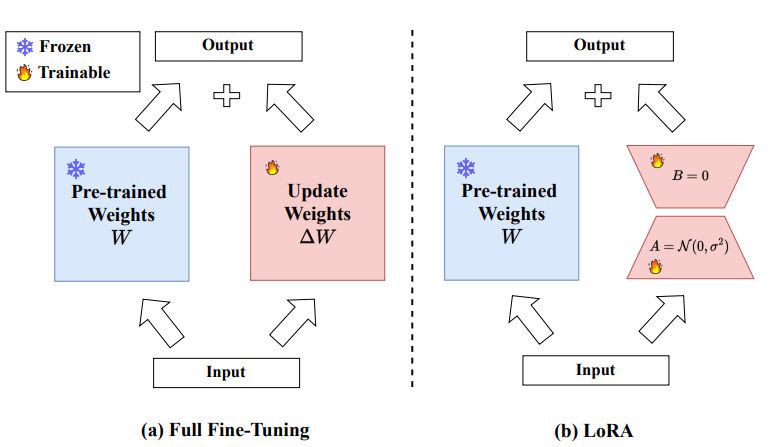
对于论文中的结果进一步描述:
1、LoRA作用在Transformer的那个参数矩阵:
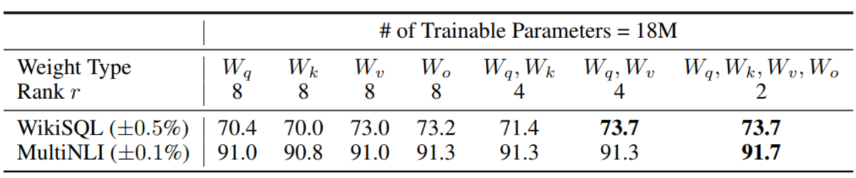
从上面分析:可以将微调参数平均分配到$W_q$和$W_v$的效果更加好
😶🌫️代码
lora_config = LoraConfig(
r=8, # 低秩矩阵秩
alpha=16, # 缩放因子,一般指定为r的两倍
dropout=0.1, # dropout 比例
target_modules=["attention.self.query", "attention.self.key", "attention.self.value", "intermediate.dense"], # 在这些层添加 LoRA
)
lora_model = LoraModel(model, lora_config)
2.2 QLoRA
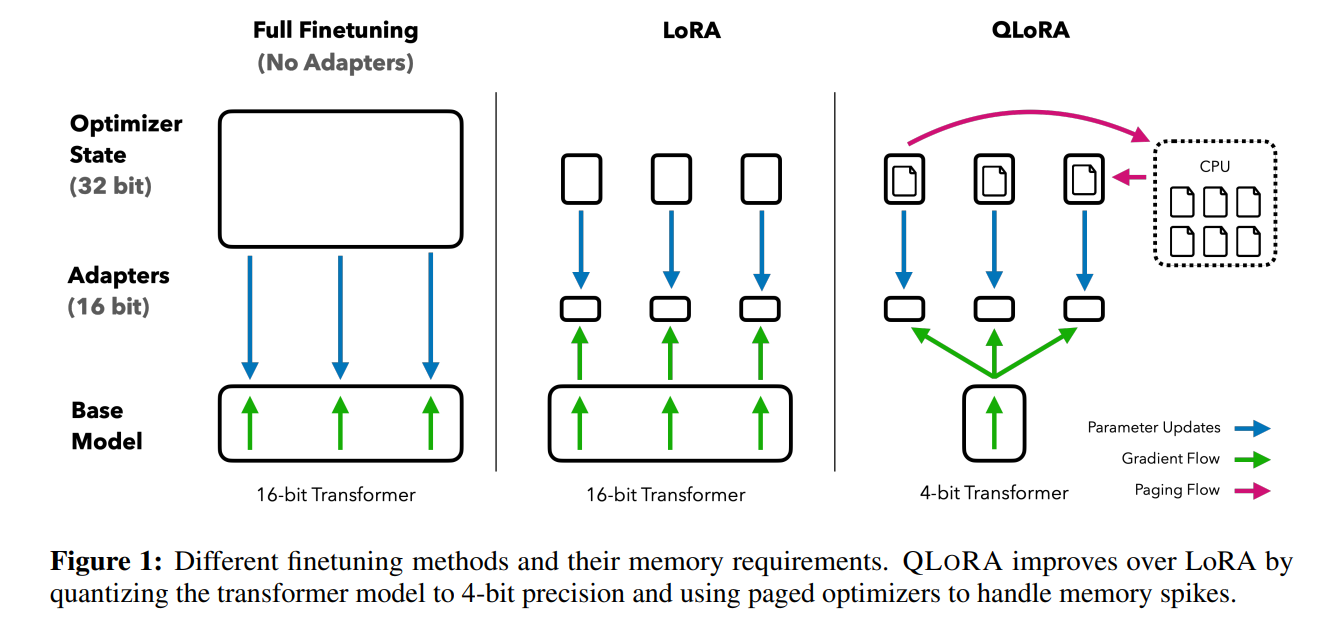
QLoRA的最后一个工作则是将量化的思想和LoRA的低秩适配器的思想结合到一起拿来对大模型进行微调。具体来讲,对于LLM的参数$W$,首先将它量化到NF4的精度,在进行特征计算时,通过双重反量化将它还原到BF16精度。同LoRA一样,QLoRA也在原参数一侧添加了一个与原参数并行的低秩适配器,它的精度是BF16。
双重量化:
\[doubleDequant(c_{1}^{FP32},c_{2}^{k-bit},W^{k-bit}) = dequant(dequant(c_{1}^{FP32},c_{2}^{k-bit}), W^{4bit})\\= W^{BF16}\]2.3 Adapter
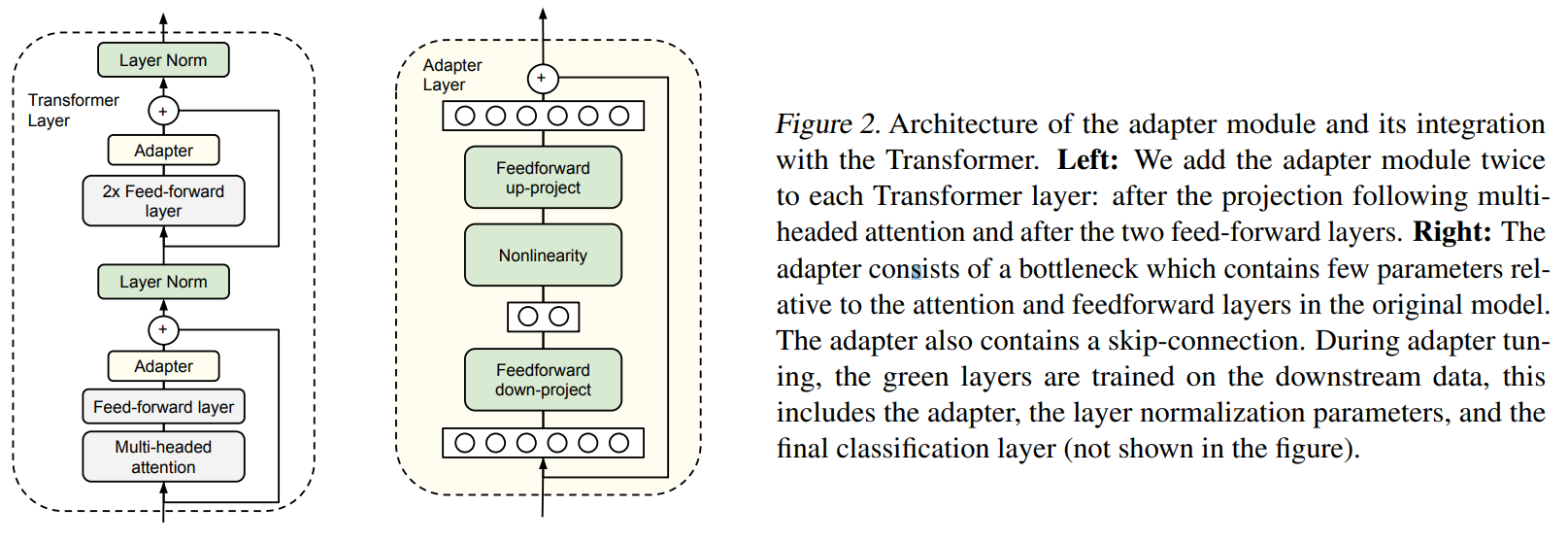
结构上很容易理解就在原始的Transformer模块中添加一个$Adapter \quad Layer$。具体微调过程为:将输入特征维度为:m缩小到d。那么得到的每一层的参数量(包含bias)就是:$2md+d+m$。通过设置$m \ll d$。整个实验过程中模型参数大概为原始参数的0.5-8%,在Adapater内部有一个跳跃连接。使用跳跃连接,如果projection layer的参数初始化为接近零,则模块将初始化为近似恒等函数。
在使用 adapter 进行调整时,adapter layer 被添加到预训练的语言模型中,但在预训练阶段,其内部参数通常是冻结的,不会进行优化。这意味着在预训练阶段,adapter layer 中的参数保持不变,不会随着语言模型的参数更新而更新。然而,在微调阶段,adapter layer 中的参数会被解冻,并与整个模型一起进行微调,以适应特定的目标任务。在微调过程中,adapter layer 的参数会根据新任务的损失函数进行优化,以使模型在新任务上表现更好。
参考
1、https://github.com/liguodongiot/llm-action
2、https://arxiv.org/pdf/2106.09685
3、http://arxiv.org/abs/1902.00751
4、https://arxiv.org/abs/2103.10385
5、https://arxiv.org/pdf/2101.00190
6、https://arxiv.org/pdf/2407.11046v4
7、https://huggingface.co/docs/peft/package_reference/lora
