LLM 生成策略全解析:从 Beam Search 到 Top-p 采样
我们都知道在使用dl模型(比如图像分类)最后的结果都是一个概率值(比如100种类别,输出就是每种类别的概率),常见的作法就是直接取概率最大的作为最终预测结果,但是LLM里面也用这种方式合理吗(毕竟文本也需要考虑整体的不单单就是让下一个字最佳即可)。本文主要介绍:Beam search、Greedy search等LLM生成策略方式。
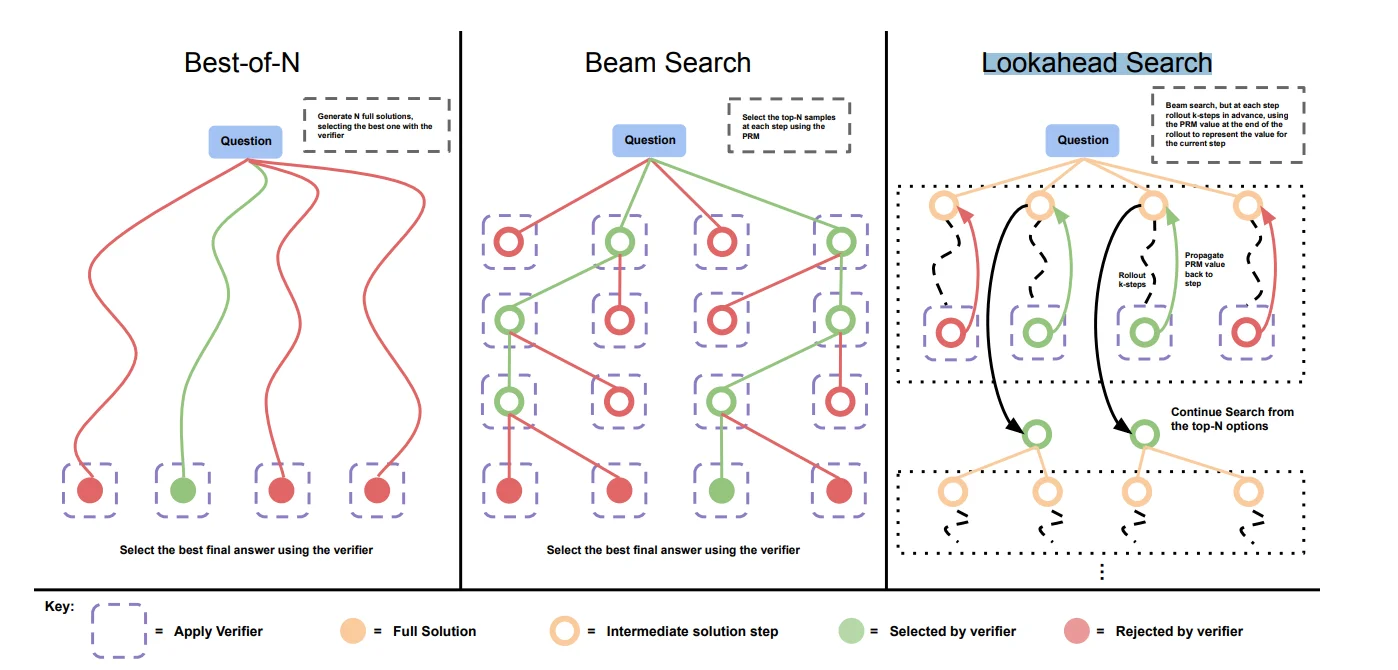
Beam Search
区别于Greedy search每次都会选择一个最优的输出,Beam search则是会选择一个 束宽(beam size)(k)也就是在生成过程中会从生成的内容中选择k个最为第t步的输出,而后在t+1步中会将前k步的输出结合起来构成新的输出。
温度调节(Temperature Scaling)
比如说温度调节使用:
@torch.no_grad()
def generate(self, idx, eos, max_new_tokens, temperature=1.0, top_k=None):
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.params.max_seq_len else idx[:, -self.params.max_seq_len:]
# forward the model to get the logits for the index in the sequence
logits = self(idx_cond)
logits = logits[:, -1, :] # crop to just the final time step
if temperature == 0.0:
# "sample" the single most likely index
_, idx_next = torch.topk(logits, k=1, dim=-1)
else:
# pluck the logits at the final step and scale by desired temperature
logits = logits / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
if idx_next==eos:
break
return idx
上面生成器中,设定最大生成长度max_new_tokens,通过前馈计算(self(idx_cond))生成之后通过选取最后时间步的概率($b,t,vocab_size \rightarrow b, 1, vocab_szie$)这样就相当于得到模型新的输出(每个词的概率)当选择的温度参数为0时,模型会选择最可能的 token(即选择 logits 中最大值对应的索引)。这是确定性的选择。反之就会,logits 会被 temperature 除以,从而影响选择的多样性。较高的温度值会使得概率分布变得更均匀,增加随机性;较低的温度值会让概率分布更加尖锐,使得选择更有偏向性。
从上面代码其实也很容易发现 温度系数是如何影响输出的:
通过温度系数$T$来平滑最后输出:
当$T=1$ 时,公式恢复为标准的softmax计算,logits 被直接用来计算概率。
当$T>1$ 时,logits 被缩小,概率分布变得更加平滑。这个时候,低概率的选项也可能被采样到,从而增加生成的多样性。温度较高时,模型的输出更加随机,生成的文本更加多样化。
当$T<1$时,logits 被放大,概率分布更加尖锐。这个时候,高概率的选项会变得更加突出,低概率的选项几乎被完全抑制,从而使模型的输出更加确定性。低温度时,模型倾向于生成高概率的单词,减少了生成的多样性。
Lookahead Search
在生成过程中,它不仅考虑当前 token,还预先评估多步生成结果的质量,以此来选择最合适的当前步骤。它是一种对未来进行前瞻评估的策略,能够平衡生成的连贯性和多样性。使用方法比较简单
probs = F.softmax(logits, dim=-1)
candidate_probs = []
for _ in range(lookahead_depth):
idx_next = torch.multinomial(probs, num_samples=1)
candidate_score = self.evaluate_candidate(idx, idx_next, eos)
candidate_probs.append((candidate_score, idx_next))
candidate_probs.sort(reverse=True, key=lambda x: x[0])
best_candidate = candidate_probs[0][1]
idx = torch.cat((idx, best_candidate), dim=1)
if best_candidate == eos:
break
