CV-MultiModal特征融合技术汇总
视觉多模态模型在结构上比较统一,一个视觉编码器(较多使用的是Vit/Resnet等)对图像信息进行处理,然后将其和文本信息一起结合然后输入到LLM模型中得到最后的结果,因此在此过程中一个最大的挑战就是:如果将不同模态信息进行结合(当然有些可能还需要考虑如何将图像进行压缩,这里主要是考虑有些图像的分辨率比较高),因此主要介绍在数据模型中如何对不同模态信息对齐的操作。
对比学习范式对模态对齐
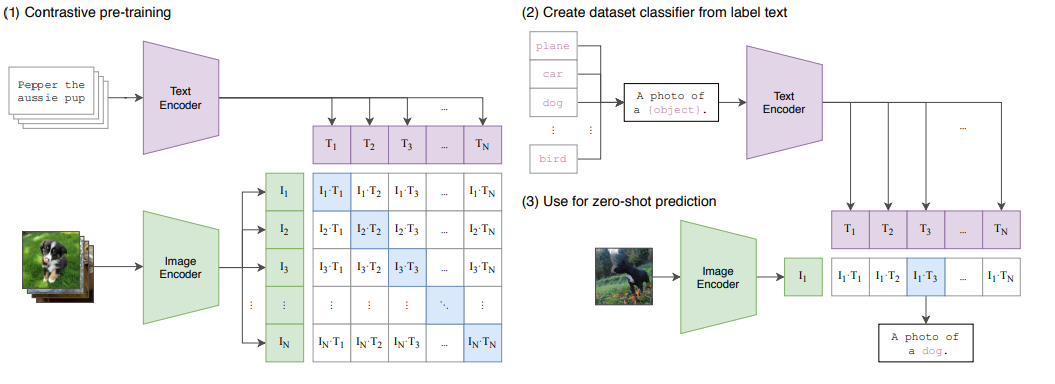
代表模型 CLIP,更加像一种 图像-文本对齐模型,按照论文里面他自己提到的计算范式:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
在将 Image 和 Text 编码完成之后,直接计算它们之间的相似度,实现模态之间的对齐。优化过程的目标是让匹配的图文对的相似度尽可能大,同时让不匹配对的相似度尽可能小。换言之,CLIP 的对比学习机制本质上是在学习一种跨模态的相似度表示。其核心机制是通过对比学习和嵌入空间对齐,将图像和文本映射到一个共享的语义空间中。
尽管 CLIP 本身并不直接包含复杂的推理能力或任务特定的知识,但它通过大规模预训练,展现出了强大的通用性和零样本学习能力。在论文中,CLIP 表现出了不俗的零样本性能,但需要注意的是,CLIP 的主要目标是学习跨模态的对齐表示,这使得它能够胜任多种任务(如图文检索、零样本分类等)。相比于传统的目标识别模型,CLIP 更像是一个多模态的基础模型,具备更广泛的适用性和灵活性。
ALBEF
BLIP
在论文 BLIP以及论文 BLIP-2中处理视觉以及文本模态信息,并不是直接编码,然后丢到LLM中进行处理,以BLIP-2模型中处理方式为例
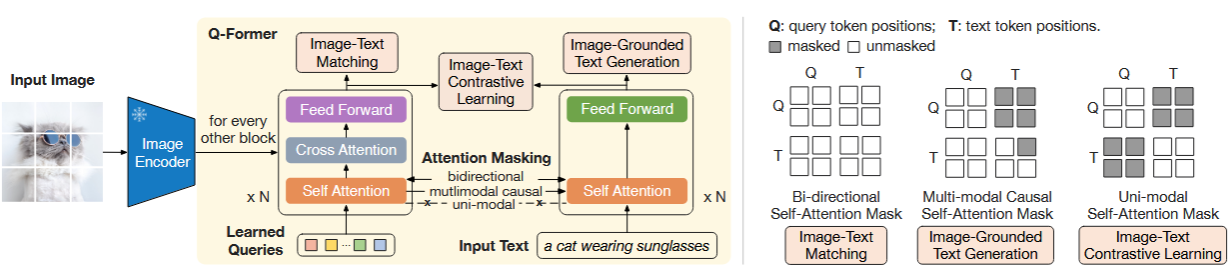
在 BLIP-2中因为同时冻结了Image Encoder以及LLM因此为了弥补不同模态之间的差异,就需要设计一个“模块”来进行表示(在论文中做法是:将Image/Text上的信息都”反映“到一个Learned-Queries上)。具体操作为:
1、ITC(Image-Text Contrastive Learning):优化目标是对齐图像特征和文本特征,也就是对齐image transformer输出的query representation与来自text transformer输出的text representation。为了避免信息泄漏,ITC采用了单模态自注意掩码,不允许query和text看到对方。计算时先计算每个query与文本embedding之间的相似度,然后选择最高的作为图文相似度
2、ITG(Image-grounded Text Generation):优化目标是给定输入图像作为条件,训练 Q-Former 生成文本,迫使query提取包含所有文本信息的视觉特征。由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由query提取,然后通过自注意力层传给text token。ITG采用多模态causal attention mask来控制query和text的交互,query可以相互感知,但不能看见text token,每个text token都可以感知所有query及其前面的text标记【半矩阵,生成式任务的常见做法】。这里将 [CLS] 标记替换为新的 [DEC] 标记,作为第一个文本标记来指示解码任务。
3、ITM( Image-Text Matching):优化目标是进行图像和文本表示之间的细粒度对齐,学一个二分类任务,即图像-文本对是正匹配还是负匹配。这里将image transformer输出的每个query嵌入输入到一个二类线性分类器中以获得对应的logit,然后将所有的logit平均,再计算匹配分数。ITM使用双向自注意掩码,所有query和text都可以相互感知。
参考
1、Learning Transferable Visual Models From Natural Language Supervision
2、BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
3、BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
4、Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
