深度学习分布式训练-2(模型并行/数据并行/流水线并行/张量并行)
前面Blog(https://www.big-yellow-j.top/posts/2025/01/03/DistributeTraining.html) 介绍了4种并行训练方式(模型并行/数据并行/流水线并行/张量并行),本文再去补充几种并行训练方式,并且对于一些内容在丰富一下,并且对所有的并行训练方式做一个总结。
1、张量并行
张量并行目的是模型参数矩阵太大,需要将他们拆分到不同设备。张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)(权重矩阵按行分割)与列并行(Column Parallelism)(权重矩阵按列分割)。假设计算过程为:$y=Ax$其中$A$为权重
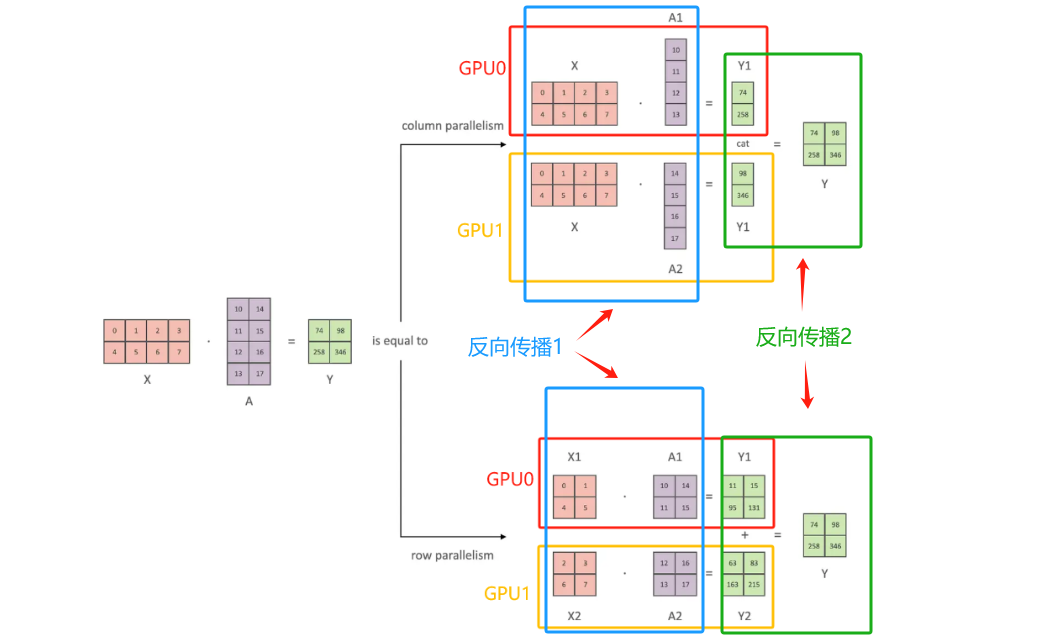
列并行操作
观察上面图像上半部分,forward部分容易理解,对于backward部分理解:第一部分计算(反向传播-1):得到两个新的Y1和Y2然后将他们进行拼接,计算梯度可以直接$\frac{\partial L}{\partial Y_1}
\frac{\partial L}{\partial Y_2}$得到梯度,第二部分计算(反向传播-2):由于x是完整的因此可以直接$\frac{\partial L}{\partial X}=\frac{\partial L}{\partial X}|{A_1}+\frac{\partial L}{\partial X}|{A_2}$
行并行操作
观察上面图像上半部分,forward分别对输入x以及参数A进行才分然后计算,对于backward理解:第一部分(反向传播-2):因为得到的Y是由两部分Y1和Y2直接相加得到结果,因此:$\frac{\partial L}{\partial Y_1}= \frac{\partial L}{\partial Y}$,第二部分(反向传播-1):$\frac{\partial L}{\partial X}=[\frac{\partial L}{\partial X_1}+\frac{\partial L}{\partial X_2}]$
对于 列并行操作由于x是完整的只需要通过 all-reduce操作(将不同设别的梯度信息“汇总”起来)。行并行操作:由于x都被拆分了,因此需要通过 all-gather(将不同GPU梯度聚合而后广播)
all-reduce、all-gather等见:All-Gather, All-Reduce, reduce-scatter什么意思?
2、专家并行
总结
参考
1、https://www.big-yellow-j.top/posts/2025/01/03/DistributeTraining.html
