LLM中的RLHF优化方法:GRPO、DPO与PPO解析
在之前blog中简单介绍了一下DeepSeek-R1可以不使用任何监督数据让模型拥有推理能力,其使用的GRPO技术这里再次具体理解一下他的具体原理,以及代码实践操作。对于GRPO参考论文(DeepSeek):https://arxiv.org/pdf/2402.03300; 对于PPO参考论文(OpenAI):https://arxiv.org/pdf/1707.06347
简单回顾LLM训练过程
在Blog里面讨论过LLM框架这里简单讨论一下LLM训练过程,一般而言在LLM中训练主要分为如下几个阶段:
- 1、预训练(Pre-Training)
这部分简单理解就是让LLM能够说“人话”,自回归模型通过前一段文本然后预测下一个文本,并且让模型能够较好的“说话”(比如说:大语言模,下一个字可以正确输出 “型”)
- 2、后训练(Post-Training)
在得到一个能够说人话的模型之后,就需要让模型能够“思考”,这部分主要分为两部分:1、监督微调(SFT Supervised Training);2、人类反馈强化学习(RLHF Reinforcement Learning from Human Feedback)。前者:顾名思义,我们首先使用监督学习方法,在少量高质量的专家推理数据上对 LLM 进行微调,例如指令跟踪、问题解答和/或思维链。希望在训练阶段结束时,模型已经学会如何模仿专家演示。后者:RLHF 利用人类反馈来训练奖励模型,然后通过 RL 引导 LLM 学习。这就使模型与人类的细微偏好保持一致
RL几个基本概念以及发展历程
简单理解RL就是:一个智能体如何在环境中做出最佳操作。
一些在RL常用的几个关键词:
1、Agent:这里可以直接理解为我们的LLM
2、State:模型当前的状态,反映了LLM在特定时刻所处的情境(可以描述为:LLM的前n-1个词)
3、Action:LLM所输出的内容,也就是智能体根据当前状态所采取的行动(LLM输出的第n个词)
4、Reward Model:奖励模型,对于LLM输出的内容进行“打分”
5、Policy:决定LLM如何输出内容的策略或规则,指导智能体在不同状态下如何行动
比如说:如何让电脑自己控制马里奥通关
为了具体的了解到GRPO原理,有必要快速了解一下强化学习发展
https://youtu.be/JZZgBu8MV4Q?si=Tr7QC6srxkZJPdsI
首先了解两个模型概念:1、Policy Model;2、Value Model。前者可以理解为LLM输出下一个词(token)的评分,后者这是评价整个过程的评分。
1、Policy Model优化。都知道在LLM训练过程中(无论是pre-training还是SFT)都是会通过GT(Ground Truth)来计算梯度,然后根据这个梯度来优化我的参数,也就是说:$\theta = \theta- \text{lr}* \text{gradient}$。分别表示:参数、学习率、梯度。在 Policy Model优化过程梯度更新为:$\theta= \theta+ \text{lr}\text{gradient}\text{reward}$(之所以用加号是因为在RL优化过程中是为了最大化奖励模型)更加直观的了解RL参数优化的 $\text{gradient}$ 和$\text{reward}$前者表示的是优化的方向,后者表示的优化的行为(比如说尝试各类投篮动作,其中投篮动作就是我们的 actor球进了就是需要的 reward)。
2、baseline、actor-critic、advanadge actor critic。但是这样随之而来会带来一个新的问题,参数优化是high variance的(过度依赖我们的reward,比如reward=0就会导致一直不更新)因此就有一个 baseline的方法(设定一个平均状态来保证不被reward过度修改),基于 baseline又提出 actor-critic方法,actor-critic方法通过将value model加入进来扮演 critic角色来评估当前策略的好坏,而 policy model扮演actor角色,通过value model来指导actor。
比如说篮球比赛,actor(policy model):球员,critic(value model):教练。两个模型一起进行训练前者进行动作(打球)后者来判断这一系列动作对未来局面影响
不过使用actor-critic这种策略对于资源消耗是比较大的因此就提出 advanadge actor critic优化策略:$A(s,a)=Q(s,a)-V(s)$也就是表示当前动作𝑎相比平均水平(V值)的好坏。
也就是说既然要更新“行为”直接计算,如果他比平均水平要好,那么我后续就要采用这个“行为”
3、TRPO,PPO,GRPO:在 TRPO中提出:$\text{ratio}\times \text{advantage}$其中 $\text{ratio}=\frac{\pi_{\text{new}}}{\pi_{\text{old}}}$也就是参数更新的模型与旧的没有更新的模型参数比值,于此同时为了保证参数的更新不会太大,还会计算一个KL散度值:$\text{KL}(\pi_{\text{old}}, \pi_{\text{new}})≤\delta$
1、对于KL散度理解而言,避免参数的更新过大;2、ratio而言表示新旧策略对动作的相对倾向
计算KL散度复杂度比较高,因此 PPO中就提出使用裁剪策略将ratio限定在一个范围中($[1-\epsilon, 1+\epsilon]$)。而在 GRPO中选择直接丢去 value model如果丢弃选择的 value model就会导致上面第2点中所提到的 baseline如何计算,GRPO比较直接,直接让模型输出多个回答,然后对回答进行评分,对于最后的 advantage计算:$\frac{r_i- mean(r)}{std(r)}$
对于奖励模型的优化:以DS-R1的为例,如何让他产出高质量/正确的思维链,一个很简单(废人)过程就是直接让人生成很多思维过程(比如比较 7.1和7.11大小,应该先怎么样,再怎么样)但是这样就会有问题:人不可能将所有问题都写出一个思维链那就有一个更加直接办法:直接让训练好的LLM自己生成思维链。参考Blog的解释对于一个奖励模型$R_{\phi}$定义一个这样的优化过程:
\[\mathrm{L}(\phi)=-log \sigma(R_{\phi}(p, r_i)- R_{\phi}(p, r_j))\]其中$p$代表输入问题,$r$代表LLM输出的的结果。其中假设$r_i$的结果优于$r_j$,那么优化过程就是让模型输出内容更加的“贴合”$r_i$
上述公式推理比较简单,通过bradley-terry 模型对于模型的输出$r_j$而最优的输出$r_i$计算概率:$P(r_j > r_i)=\frac{exp(R_{\phi}(p, r_i))}{exp(R_{\phi}(p, r_i))+ exp(R_{\phi}(p, r_j))}$化简就可以得到:$\sigma(R_{\phi}(p, r_i)- R_{\phi}(p, r_j))$
PPO(Proximal Policy Optimization)模型
PPO是一种基于策略梯度的强化学习算法,核心思想是通过限制策略更新的幅度来保持训练的稳定性。其目标函数(通过KL散度处理)为:
\[L^{CLIP}(\theta)=\hat{\mathbb{E}}_{t}\left[\min(r_{t}(\theta)\hat{A}_{t},\operatorname{clip}(r_{t}(\theta),1-\epsilon,1+\epsilon)\hat{A}_{t})\right]\]| 其中$r_t(\theta)=\frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)}$ |
$\pi_\theta$: 当前策略参数化的策略函数
$A_t$: 优势函数,衡量动作$a_t$相对于平均水平的优势
$\epsilon$: 超参数(通常0.1-0.2),限制策略更新的最大幅度
Clipping机制:通过截断重要性采样比率,防止策略更新过大导致训练不稳定
对于上述公式里面优势函数$A_t$(用来衡量的是某个动作相对于平均水平的优势,也就是说,这个动作比平均情况好多少)具体计算公式为:$A_t=Q(s_t, a_t)-V(s_t)$,分别表示:1、$Q(s_t, a_t)$:在状态$s_t$下执行动作$a_t$得到的期望汇报;2、$V(s_t)$:状态$s_t$的平均累计期望。对于其计算可以通过GAE(广义优势估计)来进行计算
GRPO(Group Relative Preference Optimization)模型
GRPO是DPO的扩展形式,处理组级别的偏好优化问题,其核心公式:

$r^*$: 组内最优响应
$\mathcal{R}$: 包含k个响应的候选集
KL项:防止模型过度偏离初始策略,缓解模式坍塌
除去上述复杂公式直接通过下面PPO/GRPO过程进行理解
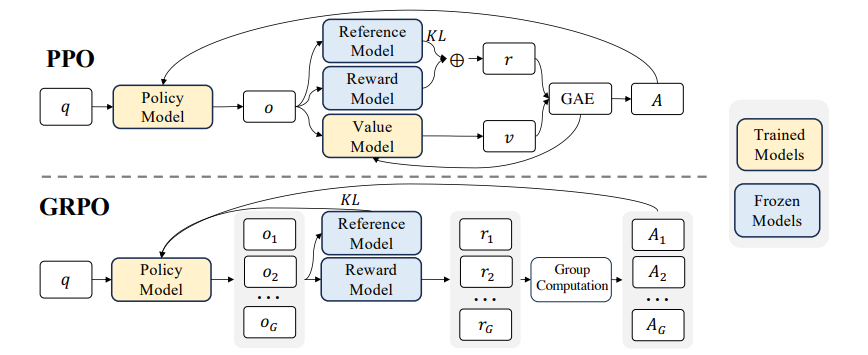
引用论文(https://arxiv.org/pdf/2402.03300) 中对于PPO和GRPO的对比分析
上图中几个比较关键词:1、Policy Model:即我们需要通过强化学习优化的模型;2、Reward Model:奖励模型,即对模型做出的决策所给出的反馈(分类打分的);3、Value Model:估计状态的价值,帮助指导策略优化(分类打分的);4、Reference Model:提供历史策略的参考,确保优化过程中策略变化不过度。
假设为优化Llama(假设参数为1B)模型,那么上述4个模型分别代表(结合hugging face训练过程中使用解释,参考如下代码):
1、Policy Model:Llama模型本身;2、Reward Model:通常是一个更加强的模型(比如说Qwen2.5-13B);3、Value Model以及 Reference Model:可以直接使用 Llama本身。
value_model = AutoModelForSequenceClassification.from_pretrained(
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
)
reward_model = AutoModelForSequenceClassification.from_pretrained(
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
)
policy = AutoModelForCausalLM.from_pretrained(
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
)
peft_config = get_peft_config(model_args)
if peft_config is None:
ref_policy = AutoModelForCausalLM.from_pretrained(
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
)
else:
ref_policy = None
trainer = PPOTrainer(
args=training_args,
processing_class=tokenizer,
model=policy,
ref_model=ref_policy,
reward_model=reward_model,
value_model=value_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
)
Code From:Code:https://github.com/shibing624/MedicalGPT/blob/main/ppo_training.py
那么在PPO/GRPO整体优化过程中的处理思路为:
首先,通过最开始的模型输出我们需要的“答案”也就是公式中的$\pi_{\theta_{old}}(o_i|q)$,而PPO和GRPO区别就在于输出的结果数量上的差异,而上述公式中所提到的 优势函数($A_t$)则是对于模型输出结果的评分,在PPO中知道计算过程为:$A_t=Q(s_t, a_t)-V(s_t)$而在GRPO中处理的方式为:$A_i=\frac{r_i- \text{mean}(r_1,…,r_n)}{\text{std}(r_1,…,r_n)}$(其中的$r$代表对每一个回答给出的评分),GRPO的优势函数很好理解,对于PPO计算公式理解:$Q(s_t, a_t)$就是LLM在当前状态下对输出所给出的评分和GRPO中相似,$V(s_t)$则是表示未来所有可能生成的 token 序列的加权回报期望值。
如何理解$V(s_t)$呢?
通过PPO训练LLM时候,会通过 Pilicy Head以及 Value Head来进行调节,第一个很好理解就是用来输出下一个词,第二个就是用来负责评估当前生成状态的价值 $V(s_t)$
而后,通过计算KL散度来保证更新模型“偏离”不会太远,通过计算优化模型与Reference Model之间KL散度来进行限制。
代码实战
不借助现有的包装好的实现PPO/GRPO推荐Github项目:https://github.com/OpenRLHF/OpenRLHF。主体结构介绍:
- 1、
models框架设计
actor.py
参考
1、https://ghost.oxen.ai/why-grpo-is-important-and-how-it-works/
2、https://yugeten.github.io/posts/2025/01/ppogrpo/
3、https://arxiv.org/pdf/2501.12948
4、https://arxiv.org/pdf/2402.03300
5、https://arxiv.org/pdf/2305.18290
6、https://github.com/hkproj/dpo-notes/blob/main/DPO_Final.pdf
7、李宏毅-介绍RL课程
8、李宏毅-RL系列课程
9、https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
10、https://youtu.be/JZZgBu8MV4Q?si=Tr7QC6srxkZJPdsI
11、TRPO:https://arxiv.org/pdf/1502.05477
12、PPO:https://arxiv.org/pdf/1707.06347
