Docunmen AI 中多视觉编码技术汇总
HuangJie 于
2025-02-19
在 wuhan 发布
⏳ 预计阅读 1 分钟
浏览量
采用不同Fushion Model
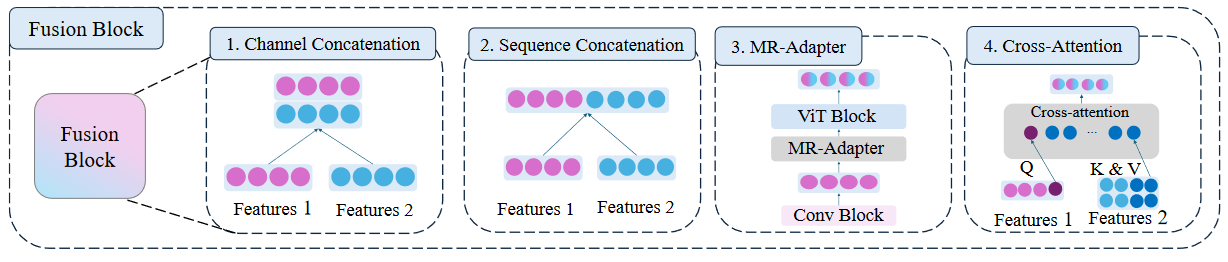
Brave [16] and Mousi [11] use sequence concatenation, LLaVA-HR [33] employs an MR-adaptor, MiniGemini [23] uses cross-attention, and Eagle [40] utilizes channel concatenation.
1、LEO

2、InternVL
3、BRAVE
4、EAGLE
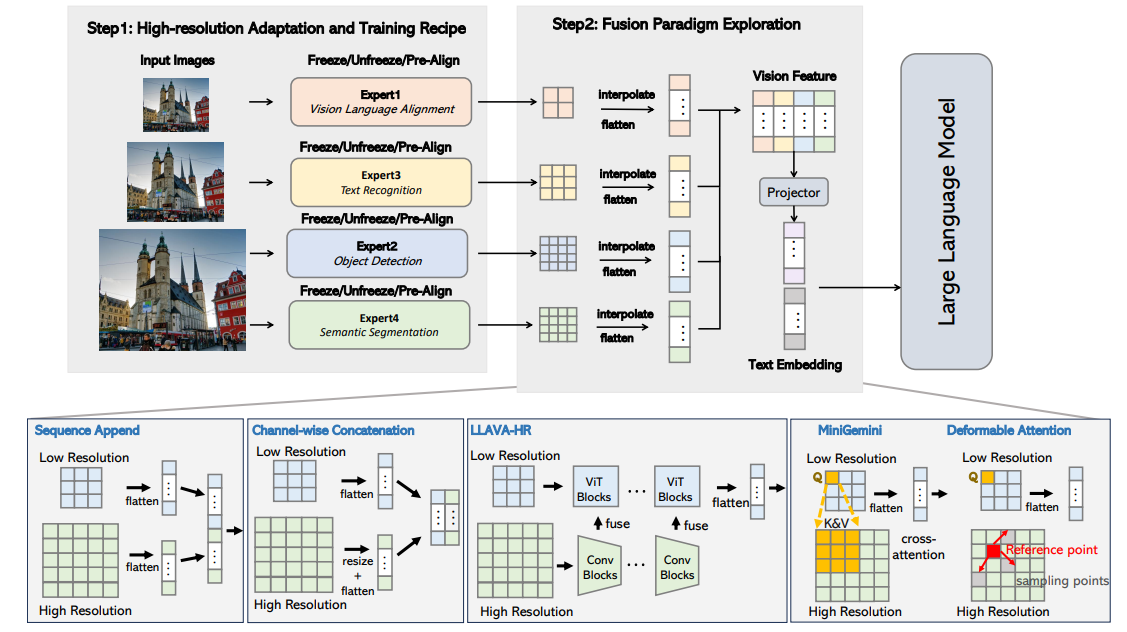
5、Mini-Gemini
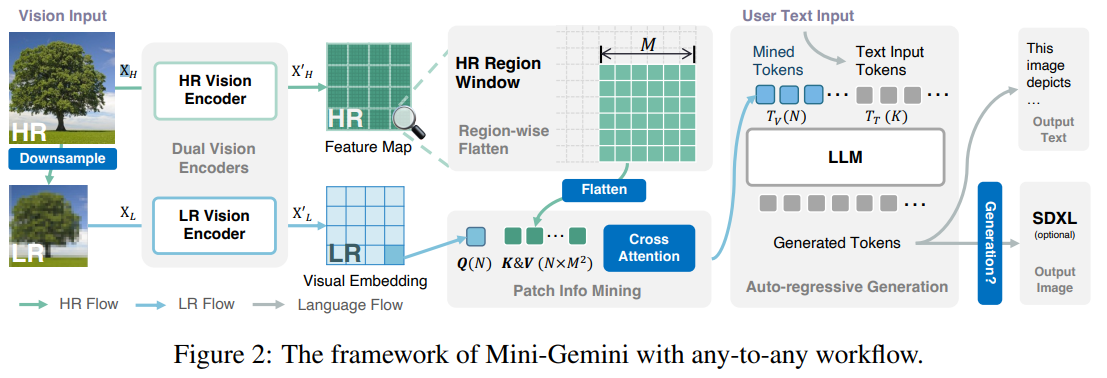
参考
1、LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
2、InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
3、BRAVE : Broadening the visual encoding of vision-language models
4、EAGLE: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
5、Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
