Docunmen AI 中图像高分辨率处理思路汇总
1、冗余内容处理办法
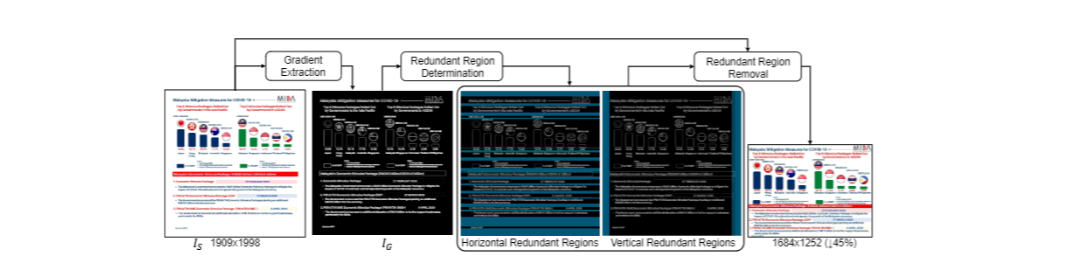
DocKylin直接对横平竖直去除冗余的像素(比如文本中大量的空白,直接通过将图片梯度转化(黑白),然后分别将水平/竖直方向上的“没有元素”内容进行连接然后继续去除,可以实现模型对高分辨率的图像的处理)
对于编码后的token,认为对于token存在必要/非必要的token,通过聚类算法降低token维度,处理为2类(根据相似的token的数量来确定那些是必要的那些是非必要的),而后通过计算这两类之间的余弦相似度将非必要的token aggregate到必要的token中
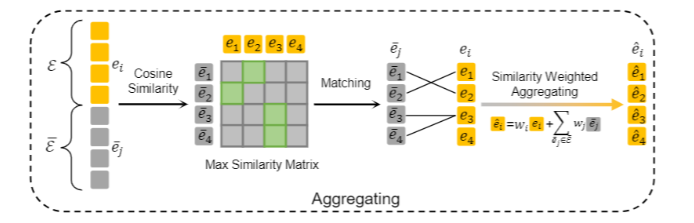
聚类算法:

实际测试:1、裁剪iamge;2、减少冗余token测试效果:

2、动态分辨率处理办法
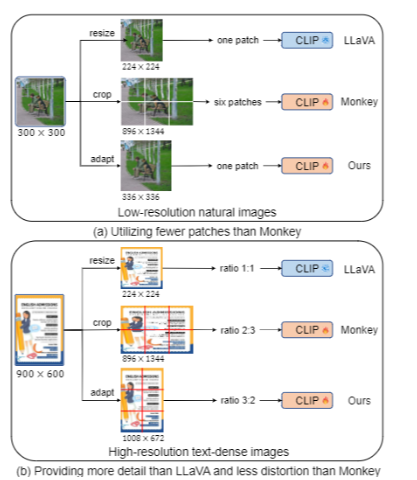
AdaptVision:动态的处理图像分辨率(对比LLaVa($224 \times 224$), Monkey($896 \times 1344$)都是将图片固定到一个分辨率)
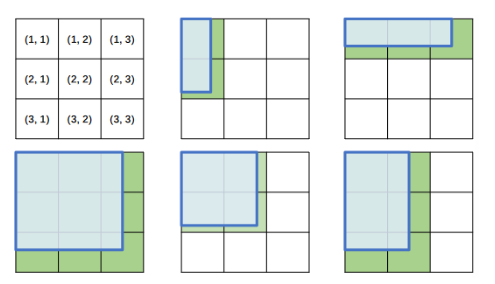
处理思路比较简单,类似:提前创建一个$1008 \times 1008$的“画布”,然后将画布切割为$3 \times 3$然后将图像放到画布左上角,看其所占用的区域范围,根据空间将图像转化到指定大小。
类似的思路如论文1、论文2中处理思路,对于 动态分辨率处理,方法如下:
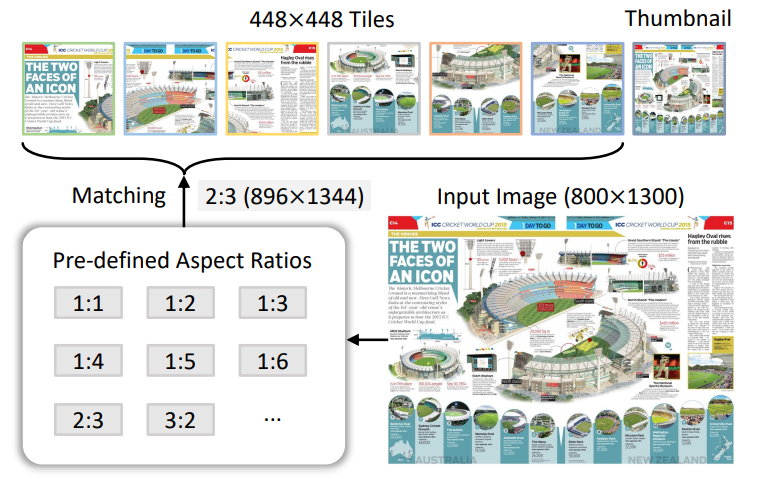
因为都要将图片切片(分割成不同的小patch)区别之前做法可能是先将图片固定到一个尺寸,然后切割,上面两篇论文中动态分辨率处理思路就是:对于每个patch先提前设定一个大小(比如说每个patch都固定尺寸为$448\times 448$)然后在设定一个 横纵比范围,然后将图片筛选出合适的 横纵比。比如说上面图片:
- 输入:$800\times1300$
- 挑选合适比例,因为每个
patch都是$448\times448$,因此:$800/448: 1300/448≈2:3$,因此先将图片扩大到:$448\times2,448\times3=896\times1344$,然后再去切割即可
3、$DC^2$
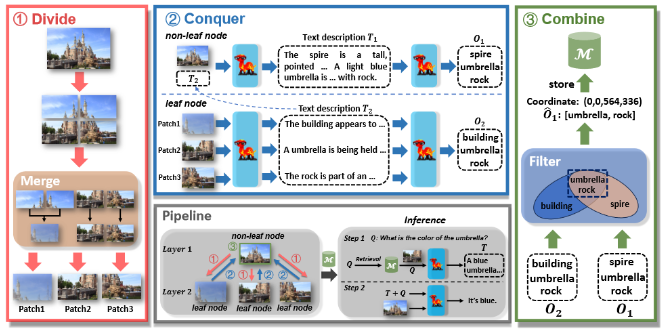
DC^2:处理高分辨率图像(4K/2K),论文提出通过将图像固定到一个固定的分辨率会导致较大的信息损失,增加模型的不确定性,但是可以通过添加文本信息进行补偿(将文本和image进行融合)。论文通过3步处理高分辨率图像:1、Divide:将图像切割为4部分(切割过多的patch会破坏目标完整性),然后计算每个部分之间的相似性,通过设定阈值来对形似部分通过 分层聚合的方式进行合并。2、Conquer:对于切分(并且进行合并)的patch以及完整的patch都生成文字描述,并且通过对生成的描述再通过llm抽取出里面的实体。并且将内容加入到完整的图像中并且进行类似处理。3、Combine:通过对leaf node以及no-leaf node提取到的实体,对两部分实体计算交集
参考:
1、DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
2、AdaptVision: Dynamic Input Scaling in MLLMs for Versatile Scene Understanding
3、How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
4、LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
