深度学习Word Embedding原理及其代码
Word Embedding:将文本处理为计算机可以理解的数字表示。一种最简单的表示就是直接用one-hot,我建立一个字典,然后对每个字符都进行编码比如说:你好(表示为:10,01)。但是这种编码会有一个问题:丧失语义信息,比如说对于文本:喜欢和爱这两个词可能会被编码成:1000和0100,但是从语义上这两个词所表达的含义应该是相似的,但是用one-hot编码无法表示这种关系。
静态词向量预训练模型
1、Word2vec词向量
Word2vec其实就是一个简单化的神经网络结构,但是为了文本能够顺利的输入到模型,首先做法还是:对文本通过one-hot进行编码然后通过一个线形层进行处理(没有激活函数)更具模型的输入和输出差异,有两种范式:1、Skip-gram;2、CBOW。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。 Skip-Gram模型输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
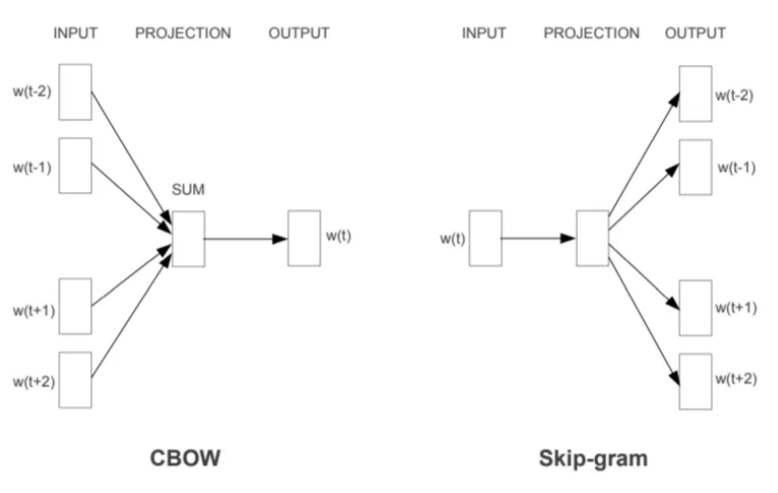
| CBOW模型,对于输入词表,设定一个窗口大小然后计算目标词的概率。比如输入文本:预训练模型。对中间词“练”给mask然后设定窗口大小,再去计算概率值:p(练 | 预,训,模,型) |
| Skip-gram模型:还是按照上面例子为例,比如输入文本:预训练模型。对于skip-gram则是计算(窗口=2):P(预 | 练)….的概率值。 |
2、GloVe词向量
Glove是一个典型的基于统计的获取词向量的方法,基本思想是:用一个词语周边其他词语出现的次数(或者说两个词共同出现的次数)来表示每一个词语,此时每个词向量的维度等于词库容量,每一维存储着词库对应序号的词语出现在当前词语周围的次数,所有这些词向量组成的矩阵就是共现矩阵。
比如说(共现矩阵表示的是在文本中两个词同时出现次数,比如说i like两个词出现在一起次数是2):
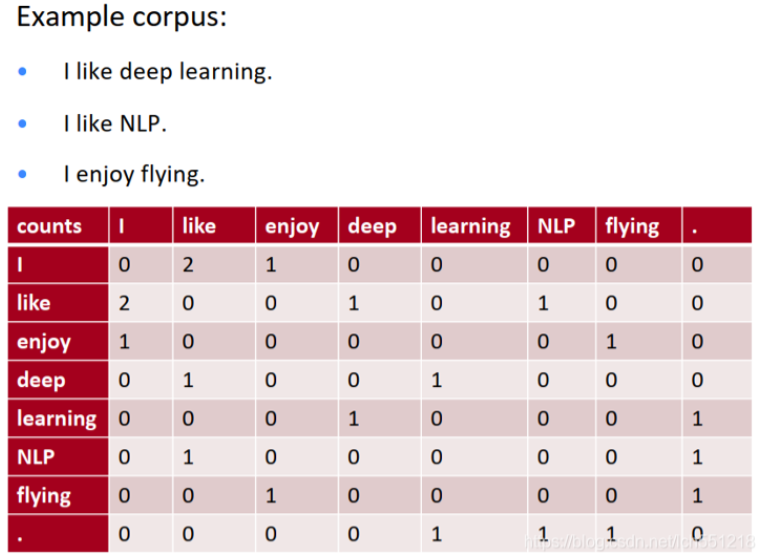
不过这样会导致一个文本,矩阵特别稀疏并且矩阵非常大维度高。
动态词向量预训练模型
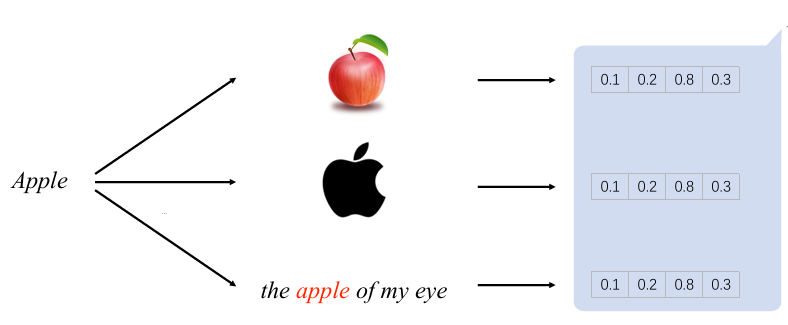
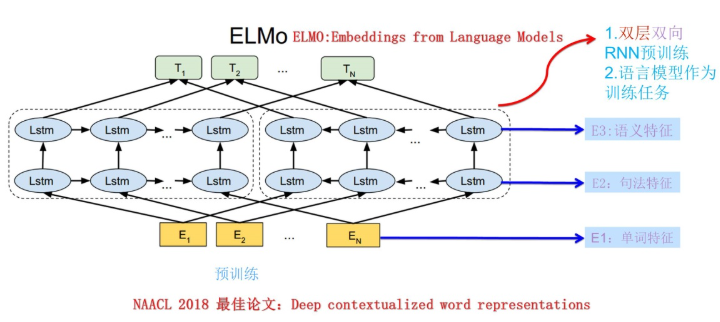
动态词向量表示为例解决静态词向量无法理解一词多义的现象,不同的数据集中同一个词的表示含义可能是不同的,而且也有可能是该数据集特有的一些含义,虽然静态的词向量可以表现出多义,但是应用在这种情况下可能就显得不太够了,因此,我们需要根据数据集的自身特点来对词向量进行微调,这就是动态词向量。比如说模型ELMo:
补充
不过就目前LLM使用的技术而言,大部分模型在处理文本过程中一致的过程是:首先对输入的文本通过 tokenizer进行处理(这个就是直接将文本拆分成数字表示),而后在通过 embedding进行处理(编码到所需要的维度),而对于 tokenizer只需要更具自身文本数据集进行训练或者直接使用预训练好的。
from Qwen.tokenization_qwen import QWenTokenizer
tokenizer_qwen = QWenTokenizer('./Qwen/qwen.tiktoken')
text = "陈准,字道基,颍川郡许昌(今河南许昌)人。西晋官员。"
encoded_input_glm = tokenizer_glm(text, return_tensors='pt')
# 输出
{'input_ids': [100348, 99308, 3837, 18600, 44793, 74046, 3837, 119251, 100410, 106317, 99454, 100763, 9909, 36171, 104185, 99454, 100763, 7552, 17340, 1773, 60686, 100850, 105404, 1773], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
encoded_input_qwen = tokenizer_qwen.encode(text, return_tensors='pt')
# 输出: [[100348, 99308, 3837, 18600, 44793, 74046, 3837, 119251, 100410, 106317, 99454, 100763, 9909, 36171, 104185, 99454, 100763, 7552, 17340, 1773, 60686, 100850, 105404, 1773]]
print(encoded_input_qwen, len(encoded_input_qwen[0]))
embedding_out = nn.Embedding(num_embeddings= tokenizer_qwen.vocab_size, embedding_dim=768)(encoded_input_qwen)
print(embedding_out.shape) # 1 24 768
input_ids: 这个列表包含了输入文本经过分词器(tokenizer)处理后的标记化(tokenized)ID。这些ID是对应每个词或子词的唯一标识符,通常来自于模型的词汇表。每个整数表示文本中的一个分词(token)。
token_type_ids: 这个列表表示每个token属于哪一部分的输入(例如,句子A或句子B),通常用于处理双句输入(例如问答任务)。对于单一输入文本,token_type_ids一般全为0。如果是双输入任务(如句子对任务),可以通过0和1来区分两个句子。
attention_mask: 这是一个二进制列表,表示每个token是否应该被模型关注。1表示模型应该关注该位置的token,0表示该位置的token被遮蔽(通常用于填充部分)。这有助于模型知道哪些token是实际数据,哪些是填充的虚拟token。
参考
1、https://code.google.com/archive/p/word2vec/
2、https://www.big-yellow-j.top/posts/2025/02/03/pos-embedding.html
