传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 都是通过弱学习机(weak learners)来对目标进行预测(分类)。但是,以决策树算法为例,决策树算法在递归过程中,可能会过度分割样本空间,最终导致过拟合。集成学习 (Ensemble Learning) 算法的基本思想就是将多个弱学习机组合,从而实现一个预测效果更好的集成学习机1。集成学习在统计(Statistical)、 计算(computational) 以及 表示(representation) 上相较之弱学习机有较大改善2。Bagging和Boosting对比如下:
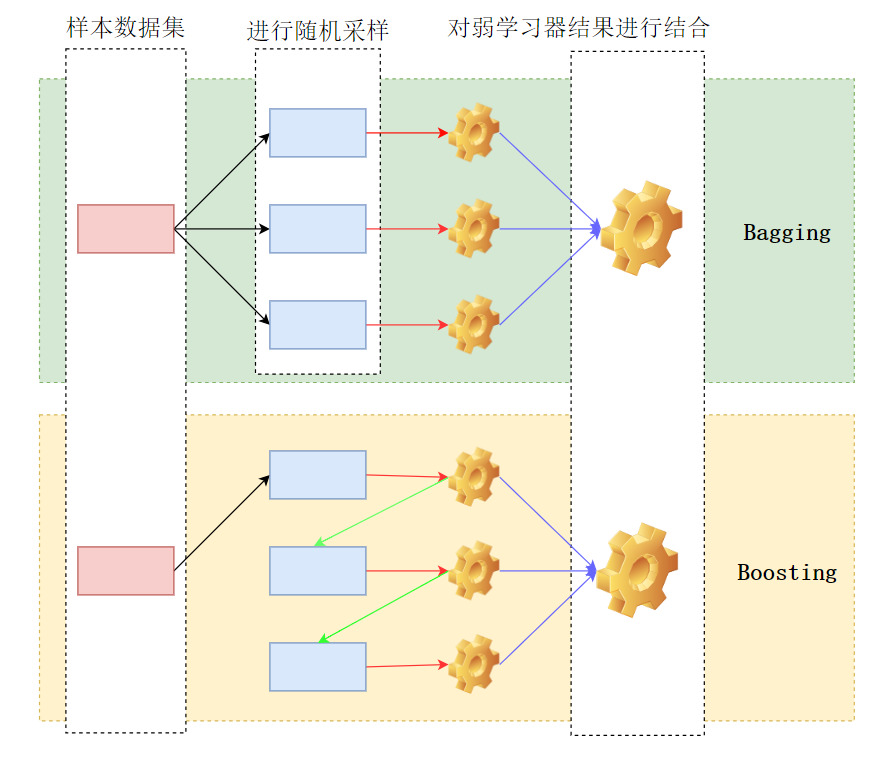
红色线条代表训练过程;绿色线条代表
Boosting更新权重得到的权重训练集;蓝色线条代表结合策略;中间蓝色方块代表得到的训练集(Bagging通过随机采样,Boosting则是更新权重得到训练集)
1 Bagging
Bagging方法是一种通过生成多组预测值,然后对这些预测值进行“聚合”的一种方法3。Bagging的算法思路为4:
- 1、每次采用有放回的抽样从训练集中取出$n$个训练样本组成新的训练集
- 2、对得到的新的训练集,通过模型进行训练得到$M$个子模型:${h_1,…,h_M}$
- 3、对于不同的任务所采用的“聚合”方法不同:对于回归任务则是直接对每一个子模型得到的训练结果直接进行平均。而对于分类任务则是对不同子模型得到的结果进行投票。
1.2 Random Forest
Random Forest5是一种利用决策树算法(决策树算法如:ID36决策树算法(基于香农熵进行节点分裂),CART7决策树算法(基于Gini不纯度进行节点分裂),C4.58决策树算法(基于信息增益比进行节点分裂))作为弱学习机的Bagging集成学习算法。
在论文5中,作者对于
Bagging的优势描述如下:
1、通过bagging可以提高准确率,当随机特征被选取时
2、Bagging可以被用来对树的泛化误差(The Generalization Error $PE^*$)进行评估,于此同时也可以对强度(strength)以及相关性(correlation)进行评估
Random Forest较之Adaboost拥有更加好的鲁棒性以及对更强的抗噪声能力(more robust and respect to noise)。其算法思路和bagging的基本思路一致:
- 给定训练数据集 (Training set) :$T$,对训练数据集进行自助法采样(
Boostrap Sampling) 得到一系列样本子集:${T_1,…,T_k}$,根据决策树算法$h$对样本子集构建对应的决策树:$h(x, T_k)$。在决策树每个节点进行分裂时,从全部$K$个特征空间均匀随机的选择一个特征子集(一般选择$log_2K$),然后从这个子集中选择一个最优分裂特征来构建决策树。
在分类任务中,通常将那些不属于类别$x$的样本称之为 out-of-bagged 有论文中通过利用 out-of-bag 的方差估计来估计任意分类器的泛化误差
2、Boosting
Boosting算法相较之Bagging算法区别在于:Bagging是通过bootstrap sampling获取样本之后,而后去对抽取样本来构建树。而Boosting每一颗树都是通过先前的树的信息来进行构建。Boosting基本思想:通过产生数个简单的、精度比随机猜测略好的粗糙估计(Boosting算法中称为弱规则$h_1,…,h_k$),再将这些规则集成构造出一个高精度的估计,其算法步骤如下:
- 1、利用初始化训练样本集训练得到一个弱学习器
- 2、提高被弱学习器误分的样本的权重,使得那些被错误分类的样本在下一轮训练中可以得到更大的关注,利用调整后的样本训练得到下一个弱学习器
- 3、重复上述步骤,直至得到$T$个学习器
- 4、对于分类问题,采用有权重的投票方式;对于回归问题,采用加权平均得到预测值
2.1 Adaboost
Adaboot9其算法基本思路如下:
假设训练样本:
\(T=\{(x_1, y_1),...,(x_m,y_m)\}\)
训练集在第$k$个弱学习器的输出权重为:
\(D(k)=(w_{k1},...,w_{km});w_{1i}=\frac{1}{m};i=1,2,...,m\)
2.2 GBDT
GBDT(Gradient Boosting Decision Tree)是决策树的集成模型,按顺序训练10。在每次迭代中,GBDT通过拟合负梯度(也称为残差)来学习决策树11。比如说:假设一个对一个人年龄(40岁)进行预测,第一次迭代:30(10)(预测值(损失值));第二次迭代(在损失值10的基础上进行迭代):7(3);第三次迭代:2(1);第四次迭代:1(0)。那么可以得到最终年龄的预测值为:30+7+2+1=40。而GBDT主要有3个主要概念构成:1、Regression Decision Tree(DT);2、Gradient Boosting(GB);3、Shrinkage
GBDT is an ensemble model of decision trees, which are trained in sequence10. In each iteration, GBDT learns the decision trees by fitting the negative gradients (also known as residual errors)11

其算法过程:假设训练样本:$T={(x_1,y_1),…,(x_m,y_m)}$,最大的迭代次数为:$T$,损失函数:$L$。那么:
- 1、对弱学习器进行初始化:
- 2、进行$T$次迭代:
对于样本$i=1,2,…,m$,计算负梯度:
\[r_{t j}=-\left[\frac{\left.\partial L\left(y_{i}, f\left(x_{i}\right)\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{t-1}(x)}\]利用$(x_i,r_{ti})(i=1,…,m)$拟合一颗CART回归树,得到t个回归树,那么对于每棵回归树
2.3 XGBoost
XGBoot是一种端到端的tree Boosting方法12。其基本思想和GBDT一样。
we describe a scalable endto-end tree boosting system called XGBoost
给定拥有$m$个特征的$n$个样本数据: $D={(x_i,y_i)}(|D|=n,x_i \in R^m,y_i \in R)$通过使用 $K$ 个独立函数对结果进行预测:
\(\widehat{y_i}=\sum_{k=1}^{K}f_k(x_i), g_k \in F\)
其中:$F={f(x)=w_{q(x)}}(q:R^m \rightarrow T, w\in R^T)$为回归树空间,$q$为表示每棵树的结构,样本映射到最终的叶子节点。$T$是树中叶子的数量。$f_k$对应一个独立的树结构$q$和叶子权重。为了得到学习函数集,最小化如下正则化目标(regularized object):
\(L(\phi)=\sum_i L(\widehat{y}_i,y_i)+ \sum_k \Omega(f_k) \\
其中\Omega(f)= \gamma T+ \frac{1}{2} \lambda||w||^2\)
上式子中$L$代表损失函数,$\widehat{y}$代表预测值,$y$代表实际值,$\Omega$代表正则化项。
-
Sagi,O.&Rokach,L.Ensemble learning: A survey.WIREs Data Min & Knowl 8,e1249(2018). ↩
-
Dietterich T G. Ensemble learning[J]. The handbook of brain theory and neural networks, 2002, 2(1): 110-125. ↩
-
Meir,R.& Rätsch,G.An Introduction to Boosting and Leveraging. in Advanced Lectures on Machine Learning 118–183 (Springer,Berlin,Heidelberg,2003).doi:10.1007/3-540-36434-X_4. ↩
-
Breiman,L.Random Forests.Machine Learning 45,5–32(2001). ↩ ↩2
-
Quinlan, J. R. Induction of decision trees. Mach Learn 1, 81–106 (1986). ↩
-
Loh, W. Classification and regression trees. WIREs Data Min & Knowl 1, 14–23 (2011). ↩
-
Salzberg,S.L.C4.5:Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach Learn 16, 235–240 (1994). ↩
-
Freund,Y.&Schapire,R.E.A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting.Journal of Computer and System Sciences 55,119–139 (1997). ↩
-
Friedman,J.H.Greedy Function Approximation: A Gradient Boosting Machine. The Annals of Statistics 29,1189–1232(2001). ↩ ↩2
-
Ke,G.et al.LightGBM: A Highly Efficient Gradient Boosting Decision Tree. in Advances in Neural Information Processing Systems vol.30(Curran Associates, Inc.,2017). ↩ ↩2
-
Chen,T.&Guestrin,C.XGBoost:A Scalable Tree Boosting System. in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (Association for Computing Machinery, 2016).doi:10.1145/2939672.2939785. ↩
