class GoogLeNet(nn.Module):
"""
input_size:输入模型图片channel
out_label:输出图片类型
"""
def __init__(
self,
input_size: int=3,
num_classes: int= 1000,
dropout: float = 0.4,
dropout_aux: float = 0.7,
inception_aux: bool= True) -> None:
super(GoogLeNet, self).__init__()
self.inception_aux = inception_aux # 判断是否走分支
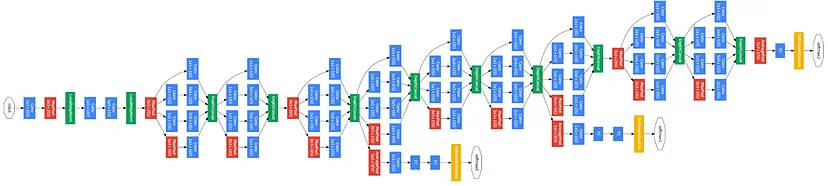
self.conv1 = ConvBlock(input_size, 64, kernel_size=7, stride=2, padding=3)
self.max_pool1 = nn.MaxPool2d(kernel_size= 3, stride=2) # 56x56x64
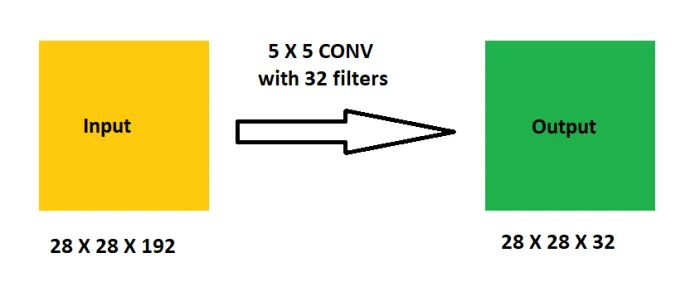
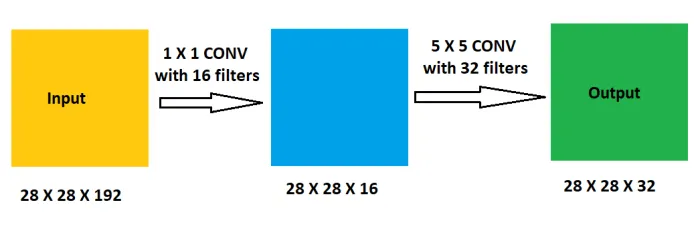
self.conv2 = ConvBlock(64, 192, kernel_size=1, stride=1) # 56x56x192
self.conv3 = ConvBlock(192, 192, kernel_size=3, stride=1, padding=1) # 56x56x192
self.max_pool2 = nn.MaxPool2d(kernel_size=3, stride=2) # 28x28x192
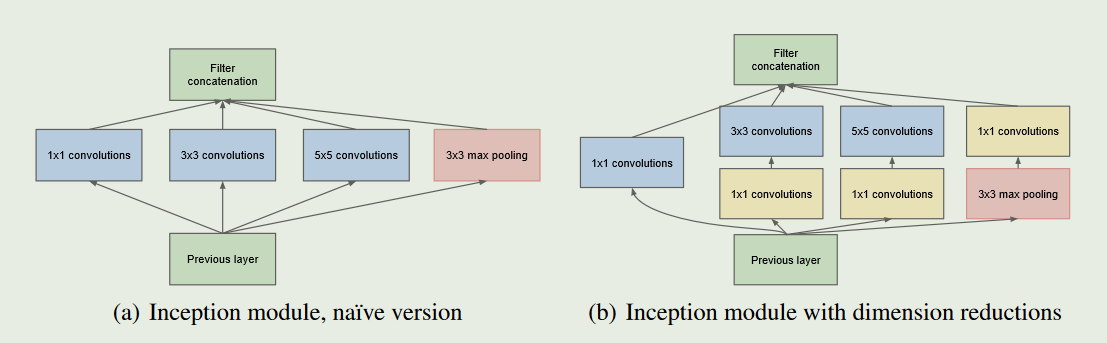
self.incept3a = InceptionModule(192, 64, 96, 128, 16, 32, 32) # 28x28x256
self.incept3b = InceptionModule(256, 128, 128, 192, 32, 96, 64) # 28x28x480
self.max_pool3 = nn.MaxPool2d(kernel_size=3, stride=2) # 14x14x480
self.incept4a = InceptionModule(480, 192, 96, 208, 16, 48, 64) # 14x14x512
# 判断
self.incept4b = InceptionModule(512, 160, 112, 224, 24, 64, 64) # 14x14x512
self.incept4c = InceptionModule(512, 128, 128, 256, 24, 64, 64) # 14x14x512
self.incept4d = InceptionModule(512, 112, 144, 288, 32, 64, 64) # 14x14x528
# 判断
self.incept4e = InceptionModule(528, 256, 160, 320, 32, 128, 128) # 14x14x832
self.max_pool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 7x7x832
self.incept5a = InceptionModule(832, 256, 160, 320, 32, 128, 128) # 7x7x832
self.incept5b = InceptionModule(832, 384, 192, 384, 48, 128, 128) # 7x7x1024
self.avg_pool = nn.AvgPool2d(kernel_size=7, stride=1) # 1x1x1024
self.linear = nn.Linear(1024, num_classes) # 1x1x1000
self.dropout = nn.Dropout(dropout_aux)
# 补充判断函数
if inception_aux:
self.inception_aux1 = InceptionAux(512, num_classes, dropout)
self.inception_aux2 = InceptionAux(528, num_classes, dropout)
else:
self.inception_aux1 = None
self.inception_aux2 = None
def forward(self, x):
x = self.conv1(x)
x = self.max_pool1(x)
x = self.max_pool2(self.conv3(self.conv2(x)))
x = self.incept3a(x)
x = self.incept3b(x)
x = self.max_pool3(x)
x = self.incept4a(x)
if self.inception_aux1 is not None:
aux1 = self.inception_aux1(x)
x = self.incept4b(x)
x = self.incept4c(x)
x = self.incept4d(x)
if self.inception_aux2 is not None:
aux2 = self.inception_aux2(x)
x = self.incept4e(x)
x = self.max_pool4(x)
x = self.incept5a(x)
x = self.incept5b(x)
x = self.avg_pool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.linear(x)
return x, aux2, aux1