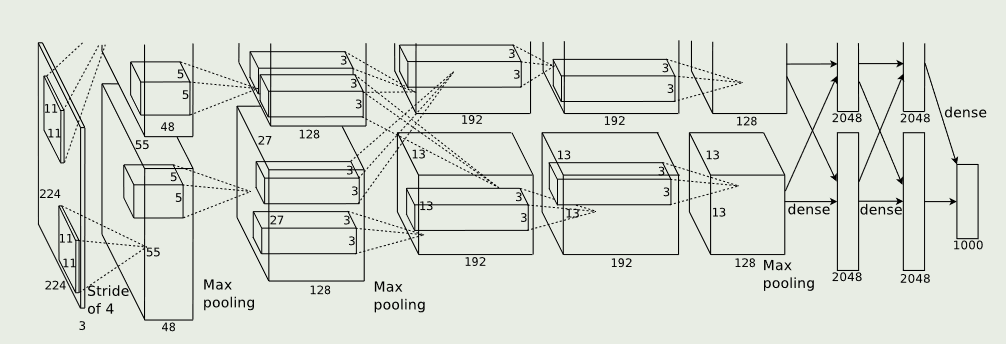
论文创新点:
1、为了避免全连接层出现过拟合,AlexNey在模型里面添加dropout(模型优化方法:在全连接层,避免所有的神经元都起到作用,也就是说选择性的忽略部分神经元)(原始论文使用的数据集为LSVRC-2010包含1000种种类的数据)
2、通过GPU进行并行训练。原文作者使用的是GTX 580只有3GB,对于如此大的训练集是完全不够用的,因此作者思路是:借助GPU之间的并行(两块(作者使用的是两块)GPU之间彼此交换memory)作者对此描述为:
将一半的内核(或神经元)放在每个 GPU 上,还有一个额外的技巧:GPU 仅在某些层中进行通信。这意味着,例如,第 3 层的内核从第 2 层中的所有内核映射获取输入。但是,第 4 层中的内核仅从驻留在同一 GPU 上的第 3 层中的那些内核映射获取输入
The parallelization scheme that we employ essentially puts half of the kernels (or neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers. This means that, for example, the kernels of layer 3 take input from all kernel maps in layer 2. However, kernels in layer 4 take input only from those kernel maps in layer 3 which reside on the same GPU.
3、overlapping pooling 作者在原始论文中提到通过对池化层设置:stride=2、kernelsize=3x3,可以提高判断的准确率以及模型更难过拟合。也就是说通过设置:$s<z$来设置overlapping pooling。争对添加overlapping pooling来避免过拟合。卷积神经网络:卷积层相当于回归系数,池化层相当于选择代表。避免过拟合,对于图片只有充分的获取图片信息才能更加好的增强模型的泛化能力,当选择$s=z$时,只对部分区域(且该区域不会在后续出现)选择出一个“代表”。
4、Local Response Normalization(LRN),计算公式如下:
$$
b_{x,y}^{i}= a_{x,y}^{i}/(k+ \alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{j})^2)^\beta
$$
$a(i,x,y)$:代表第i个卷积核在特征图中(x, y)位置的输出(经过 ReLU)
$b(i,x,y)$:代表局部响应正常化的输出
$N$:卷积核的数量
$n$:调整卷积核数量,作者选择的为5
$k,\alpha, \beta$:可调节参数,作者选择:$k=2,\alpha =10e-4, \beta= 0.75$
计算列子如下:
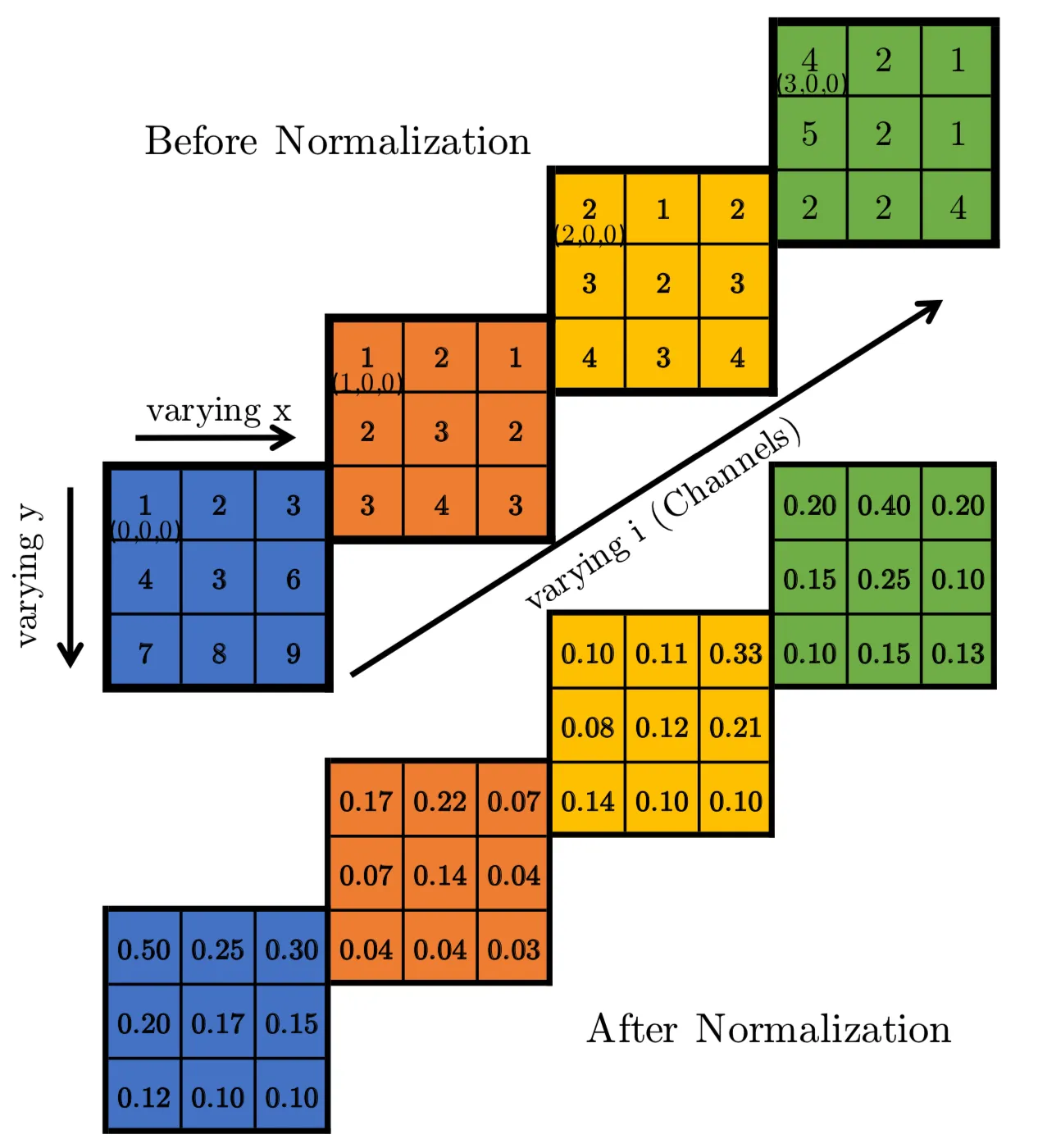
此时定义卷积核数量为:4;$k=0, \alpha= 1, \beta= 1, n=2$,此时LRN为:$b(i,x,y)= a(i,x,y)/ \sum a(i,x,y)^2$;计算如下:对于$(0,0,0)= ((0,0,0)^2+ (1,0,0)^2)= (1/(1+1))$,$(1,0,0)=((0,0,0)+(1,0,0)+ (2,0,0))= 1/(1+1+4)$
本次模型使用的数据集:http://download.tensorflow.org/example_images/flower_photos.tgz
该集合包含5中花的种类
import torch
import torch.nn as nn
import os
from shutil import copy
import random
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.optim as optim
import torchvision
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
device = ('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
cpu
# 对数据集合分类
class File_Split():
"""
对文件进行分类
输入:花种类数据
输出:划分test、train数据(9:1)
"""
def __init__(self, file):
self.file = file
def make_file(self, file_path):
"""
对于数据集,构建训练集,测试集文件夹
"""
if not os.path.exists(file_path):
os.makedirs(file_path)
# file = '../data/flower_photos'
def file_split(self):
"""
数据划分,将指定数据丢到指定的文件夹里面,实现数据的分类
"""
flower_label = [cla for cla in os.listdir(self.file)] # 输出所有花类的类别
# 构建训练集文件夹
for label in flower_label:
self.make_file('../data/flower_data/train/'+ label)
# 构建测试集文件夹
for label in flower_label:
self.make_file('../data/flower_data/test/'+ label)
splite_rate = 0.1 # 选择划分比例
for label in flower_label:
path = self.file+ '/'+ label+ '/'
image_list = os.listdir(path) # 对于一类花的路径全部存储
eval_index = random.sample(image_list, k= int(len(image_list)* splite_rate), random_state=) # 得到划分的数据路径
for image in image_list:
if image in eval_index:
# 测试集数据
image_path = path+ image
new_path = '../data/flower_data/test/'+ label
copy(image_path, new_path)
for image in image_list:
if image not in eval_index:
# 训练集数据
image_path = path+ image
new_path = '../data/flower_data/train/'+ label
copy(image_path, new_path)
print('Done!!')
# file = '../data/flower_photos'
# fs = File_Split(file= file)
# fs.file_split()
# 得到图片的均值与方差
def getMeanAndBias(dataset):
'''
输入:
iter_dataloader 要求:元素为tensor类型、转换为torch.utils.data.Dataset类
'''
# 注意batch_size的用法。这种条件下,数据集会被逐样本分割,而不是成批在一起
data_iter = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
means = torch.zeros(3)
bias = torch.zeros(3)
for img, _ in data_iter:
for d in range(3):
# 注意针对单个通道计算平均值和标准差的方法
means[d] += img[:, d, :, :].mean()
bias[d] += img[:, d, :, :].std()
means = means / len(data_iter)
bias = bias / len(data_iter)
return [means, bias]
# 构建AlexNet网络
class AlexNet(nn.Module):
def __init__(self, num_label= 5):
super(AlexNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 96, kernel_size= 11, stride=4, padding=2), # 3x224x224 -- 96x55x55
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 96x55x55 -- 96x27x27
) # 96x27x27
self.norm1 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta= 0.75, k=2)
self.layer2 = nn.Sequential(
nn.Conv2d(96, 256, kernel_size= 5, padding= 2), # 256x27x27
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 256x13x13
) # 256x13x13
self.norm2 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta= 0.75, k=2)
self.layer3 = nn.Sequential(
# 第3、4、5层不进行池化操作
# 于此同时 3,4,5层的<H,W>不发生改变,需要单独设计填充以及步长
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1), # 384x13x13
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1), # 384x13x13
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1), # 256x13x13
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2) # 256x6x6
)
self.fc = nn.Sequential(
nn.Linear(256*6*6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace= False),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace= False),
nn.Linear(4096, num_label)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1,6*6*256)
x = self.fc(x)
return x
model = AlexNet().to(device)
x = torch.randn((3,224,224), device= device)
y = model(x)
y.size()
torch.Size([1, 5])
# 对数据进行转换
# 计算图片均值以及方差
# transform = transforms.Compose(
# [transforms.Resize((224,224)),
# transforms.ToTensor()]
# )
# train_data = torchvision.datasets.ImageFolder('../data/flower_data/train/', transform=transform)
# test_data = torchvision.datasets.ImageFolder('../data/flower_data/test/', transform= transform)
# train_data_info = getMeanAndBias(train_data)
# test_data_info = getMeanAndBias(test_data)
data_transform = {
"train":transforms.Compose(
[transforms.Resize((224,224)), # 裁剪图片为224x224
transforms.ToTensor(),
transforms.Normalize((0.4669, 0.4252, 0.3044), (0.2449, 0.2186, 0.2238))]),
"test": transforms.Compose(
[transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.4637, 0.4248, 0.3011), (0.2502, 0.2219, 0.2292))]
)}
train_data_path = '../data/flower_data/train/'
test_data_path = '../data/flower_data/test/'
train_data = torchvision.datasets.ImageFolder(
root= train_data_path, transform= data_transform['train']
)
test_data = torchvision.datasets.ImageFolder(
root= test_data_path, transform= data_transform['test']
)
train_dataloader = DataLoader(
dataset= train_data,
batch_size= 64)
test_dataloader = DataLoader(
dataset= test_data,
batch_size= 64
)
# 定义优化函数以及损失函数
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def test_acc(data, model):
"""
data为通过分批次处理好的数据
返回测试集的准确率
"""
model.eval()
correct = 0.0
with torch.no_grad():
for x,y in data:
x, y = x.to(device), y.to(device)
pred = model(x)
correct += (pred.argmax(1)== y).type(torch.float).sum().item()
return correct/ len(data.dataset)
epochs = 21
# 没有对数据进行优化,可以选择去对数据进行优化,比如正则化、添加droup out、添加resnet连接
for epoch in range(epochs):
print('Epoch:{}\n'.format(epoch+1))
for batch, (x,y) in enumerate(train_dataloader):
size = len(train_dataloader.dataset)
model.train()
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch %100 == 0:
loss, current = loss.item(), (batch+ 1)* len(x)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
correct = test_acc(test_dataloader, model)
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}% \n")
Epoch:1
--------------------------------------------------------------------------- OutOfMemoryError Traceback (most recent call last) ~\AppData\Local\Temp\ipykernel_4792\3125045804.py in <module> 68 69 optimizer.zero_grad() ---> 70 loss.backward() 71 optimizer.step() 72 e:\Anaconda\lib\site-packages\torch\_tensor.py in backward(self, gradient, retain_graph, create_graph, inputs) 486 inputs=inputs, 487 ) --> 488 torch.autograd.backward( 489 self, gradient, retain_graph, create_graph, inputs=inputs 490 ) e:\Anaconda\lib\site-packages\torch\autograd\__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs) 195 # some Python versions print out the first line of a multi-line function 196 # calls in the traceback and some print out the last line --> 197 Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass 198 tensors, grad_tensors_, retain_graph, create_graph, inputs, 199 allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass OutOfMemoryError: CUDA out of memory. Tried to allocate 144.00 MiB (GPU 0; 2.00 GiB total capacity; 1.56 GiB already allocated; 0 bytes free; 1.59 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF